
Introduction
The Importance of Security for AI Agents
As artificial intelligence agents become more integrated into critical systems—ranging from autonomous vehicles and financial trading bots to healthcare diagnostics and industrial automation—their security and resilience are no longer optional. AI agents are increasingly responsible for making decisions in real time, often with significant consequences. This makes them attractive targets for adversarial attacks and data manipulation, which can compromise their integrity, reliability, and trustworthiness.
Overview of Threats: Adversarial Attacks and Data Manipulation
AI agents face a unique set of security challenges. Unlike traditional software, they learn from data and adapt their behavior over time. This opens up new attack surfaces, such as adversarial examples—carefully crafted inputs designed to mislead the agent—or poisoning attacks, where the training data is manipulated to introduce vulnerabilities. Data manipulation can occur at any stage, from data collection and preprocessing to model deployment and inference.
Adversarial attacks can cause AI agents to make incorrect decisions, misclassify objects, or even behave erratically. For example, a self-driving car might misinterpret a stop sign due to subtle changes in its appearance, or a chatbot might be manipulated into giving inappropriate responses. Data manipulation, on the other hand, can degrade the agent’s performance over time or introduce hidden backdoors that are difficult to detect.
Article Objectives
This article aims to provide advanced programmers and AI practitioners with a comprehensive understanding of the security landscape for AI agents. We will explore the most common types of adversarial attacks and data manipulation techniques, discuss their impact on AI systems, and introduce state-of-the-art methods for detection, defense, and self-healing. By the end of this series, you will be equipped with practical strategies and tools to enhance the security and resilience of your AI agents, ensuring they remain robust in the face of evolving threats.
Types of Adversarial Attacks on AI Agents
Evasion Attacks (Evasion of Detection)
Evasion attacks are among the most well-known adversarial threats to AI agents. In this scenario, an attacker subtly manipulates the input data at inference time to cause the AI agent to make incorrect predictions or decisions, all while the changes remain nearly invisible to humans. For example, in computer vision, an attacker might add carefully crafted noise to an image so that a self-driving car misclassifies a stop sign as a speed limit sign. These attacks exploit the model’s sensitivity to small input changes and can be executed without access to the model’s internal parameters, making them a significant risk for deployed AI systems.
Poisoning Attacks (Training Data Poisoning)
Poisoning attacks target the training phase of an AI agent. Here, the attacker injects malicious data into the training set, aiming to corrupt the learning process. This can result in a model that behaves normally on most data but fails or acts maliciously under specific conditions chosen by the attacker. For instance, in a spam detection system, an attacker might introduce emails that are labeled as non-spam but contain spam-like features, causing the model to misclassify future spam messages. Poisoning attacks are particularly dangerous because they can introduce long-term vulnerabilities that are hard to detect and may persist through model updates.
Model Extraction and Model Inversion Attacks
Model extraction attacks occur when an adversary attempts to reconstruct the internal parameters or architecture of a deployed AI model by systematically querying it and analyzing the outputs. This can lead to intellectual property theft or enable further attacks, such as crafting more effective adversarial examples. Model inversion attacks, on the other hand, aim to infer sensitive information about the training data by exploiting the model’s outputs. For example, an attacker might reconstruct images of individuals from a facial recognition model, raising serious privacy concerns.
Examples and Attack Scenarios
Adversarial attacks are not just theoretical—they have been demonstrated in real-world systems. In cybersecurity, attackers have bypassed malware detection by modifying malicious code to evade AI-based scanners. In finance, adversarial trading bots have manipulated market prediction models. In healthcare, researchers have shown that small changes to medical images can cause diagnostic AI systems to misclassify diseases, potentially leading to harmful outcomes.
Below is a simple Python example using the popular Foolbox library to generate an adversarial example for an image classification model:
python
import torch
import torchvision.models as models
import torchvision.transforms as T
from PIL import Image
import foolbox as fb
# Load a pretrained model and an image
model = models.resnet18(pretrained=True).eval()
image = Image.open("cat.jpg")
transform = T.Compose([T.Resize(256), T.CenterCrop(224), T.ToTensor()])
input_tensor = transform(image).unsqueeze(0)
# Wrap the model for Foolbox
fmodel = fb.PyTorchModel(model, bounds=(0, 1))
# Create an adversarial attack (e.g., FGSM)
attack = fb.attacks.FGSM()
label = torch.tensor([285]) # Example: 'Egyptian cat' class in ImageNet
raw, clipped, is_adv = attack(fmodel, input_tensor, label, epsilons=0.03)
# Save the adversarial image
adv_image = T.ToPILImage()(clipped.squeeze())
adv_image.save("cat_adv.jpg")
# Created/Modified files during execution:
print("cat_adv.jpg")This code demonstrates how an attacker can generate an adversarial image that looks almost identical to the original but causes the model to misclassify it. Such examples highlight the practical risks posed by adversarial attacks and the need for robust defense mechanisms in AI agent deployments.
Data Manipulation and Its Impact on AI Agents
Input Data Tampering
Input data tampering refers to the intentional alteration of the data that an AI agent receives during inference or operation. Attackers may craft inputs that are subtly modified to mislead the agent, causing it to make incorrect decisions or predictions. For example, in the context of image recognition, an attacker might add imperceptible noise to an image so that a classifier misidentifies an object. In natural language processing, adversaries can inject misleading phrases or tokens to manipulate chatbot responses or sentiment analysis outcomes. These manipulations are often difficult to detect because the changes are designed to be minimal and to evade both human and automated scrutiny.
Attacks on Training and Test Data Integrity
Attacks on data integrity target the datasets used to train or evaluate AI agents. By poisoning the training data, attackers can introduce biases or vulnerabilities that persist throughout the model’s lifecycle. For instance, if malicious samples are inserted into the training set with incorrect labels, the model may learn to associate certain features with the wrong outcomes. This can lead to systematic errors or even the creation of backdoors—hidden triggers that cause the model to behave maliciously under specific conditions. Similarly, manipulating test data can distort performance metrics, making a model appear more accurate or robust than it actually is. This undermines trust in the model’s reported capabilities and can have serious consequences in safety-critical applications.
The Impact of Manipulation on Agent Decisions
Data manipulation can have a profound impact on the decisions made by AI agents. When input data is tampered with, agents may misclassify objects, fail to detect threats, or make unsafe recommendations. In autonomous vehicles, for example, manipulated sensor data could cause the vehicle to ignore obstacles or traffic signals, leading to accidents. In financial systems, adversarial inputs might trigger unauthorized transactions or bypass fraud detection mechanisms. Poisoned training data can result in long-term vulnerabilities, as the agent’s decision-making process is fundamentally compromised. This not only affects the accuracy and reliability of the agent but also erodes user trust and can expose organizations to regulatory and reputational risks.
Practical Example: Data Poisoning in Python
To illustrate how data poisoning can affect a machine learning model, consider the following Python example. Here, we simulate a simple poisoning attack on a binary classifier by injecting mislabeled samples into the training data:
python
import numpy as np
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# Generate a clean dataset
X, y = make_classification(n_samples=200, n_features=2, n_informative=2, n_redundant=0, random_state=42)
# Simulate data poisoning: flip the labels of 10% of the samples
n_poison = int(0.1 * len(y))
poison_indices = np.random.choice(len(y), n_poison, replace=False)
y_poisoned = y.copy()
y_poisoned[poison_indices] = 1 - y_poisoned[poison_indices] # Flip labels
# Train on poisoned data
model = LogisticRegression()
model.fit(X, y_poisoned)
y_pred = model.predict(X)
# Evaluate the impact
accuracy = accuracy_score(y, y_pred)
print(f"Accuracy after data poisoning: {accuracy:.2f}")
# Created/Modified files during execution:
# (No files created in this example)This code demonstrates how even a small amount of label flipping can degrade the performance of a model. In real-world scenarios, such attacks can be more sophisticated and targeted, making them even harder to detect and mitigate.
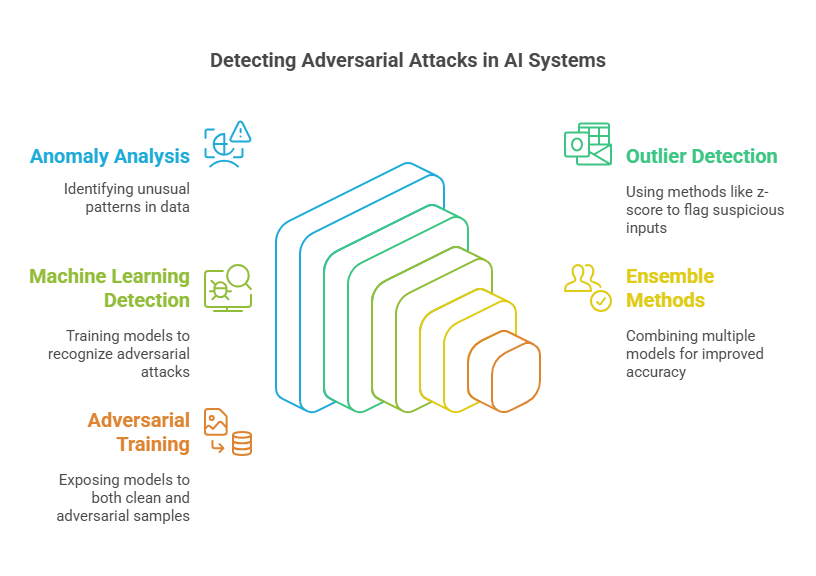
Methods for Detecting Adversarial Attacks
Anomaly Analysis and Outlier Detection
Detecting adversarial attacks often begins with identifying unusual patterns or anomalies in the data that an AI agent receives. Anomaly analysis leverages statistical techniques to flag inputs that deviate significantly from the distribution of the training data. For example, if an image classifier is suddenly presented with images that have pixel distributions far from what it has seen before, this could indicate an adversarial attempt. Outlier detection methods, such as z-score analysis, isolation forests, or autoencoders, can be used to automatically flag suspicious inputs. These techniques are especially useful in real-time systems, where rapid detection is critical to prevent compromised decisions.
Machine Learning-Based Attack Detection
Beyond traditional statistical methods, machine learning models themselves can be trained to recognize adversarial attacks. These detectors are often built as secondary models that monitor the primary AI agent. For instance, a neural network can be trained to distinguish between normal and adversarial examples by learning subtle differences in input patterns. Ensemble methods, where multiple models vote on the legitimacy of an input, can further improve detection accuracy. Some advanced approaches use adversarial training, where the detector is exposed to both clean and adversarial samples during training, making it more robust to new attack strategies.
Here is a simple Python example using an autoencoder for anomaly detection on image data:
python
import numpy as np
from keras.models import Model
from keras.layers import Input, Dense
from sklearn.metrics import mean_squared_error
# Create a simple autoencoder
input_dim = 784 # Example for flattened 28x28 images
encoding_dim = 32
input_img = Input(shape=(input_dim,))
encoded = Dense(encoding_dim, activation='relu')(input_img)
decoded = Dense(input_dim, activation='sigmoid')(encoded)
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adam', loss='mse')
# Train on normal data
X_train = np.random.rand(1000, input_dim) # Replace with real data
autoencoder.fit(X_train, X_train, epochs=10, batch_size=32, verbose=0)
# Detect anomalies
X_test = np.random.rand(100, input_dim) # Replace with real test data
X_pred = autoencoder.predict(X_test)
mse = np.mean(np.power(X_test - X_pred, 2), axis=1)
threshold = np.percentile(mse, 95) # Set threshold for anomaly
anomalies = mse > threshold
print(f"Detected {np.sum(anomalies)} anomalies in the test set.")
# Created/Modified files during execution:
# (No files created in this example)This code demonstrates how an autoencoder can be used to flag inputs that are significantly different from the training data, which may include adversarial examples.
Real-Time Model and Data Behavior Monitoring
Continuous monitoring of both model outputs and input data is essential for timely detection of adversarial attacks. Real-time monitoring systems track metrics such as prediction confidence, input feature distributions, and output consistency. Sudden drops in confidence or shifts in feature distributions can signal an ongoing attack. Modern MLOps platforms, such as Dataiku or IBM Watson OpenScale, provide dashboards and automated alerts for these metrics, enabling teams to respond quickly to suspicious activity. Integrating monitoring tools with automated retraining and validation pipelines further enhances the resilience of AI agents.
Defense Strategies and Mitigation of Adversarial Attacks
Strengthening Models with Adversarial Training
One of the most effective ways to defend AI agents against adversarial attacks is adversarial training. This approach involves augmenting the training dataset with adversarial examples—inputs that have been intentionally perturbed to mislead the model. By exposing the model to these challenging cases during training, it learns to recognize and resist similar manipulations in the future. Adversarial training can significantly improve model robustness, but it also increases computational costs and may not generalize to all types of attacks. For best results, adversarial examples should be generated using a variety of attack methods and regularly updated as new threats emerge.
Here is a simple Python example using the cleverhans library to perform adversarial training with the Fast Gradient Sign Method (FGSM):
python
import tensorflow as tf
from cleverhans.tf2.attacks.fast_gradient_method import fast_gradient_method
# Assume you have a model and (X_train, y_train) as your data
# Generate adversarial examples
epsilon = 0.1
X_train_adv = fast_gradient_method(model, X_train, epsilon, np.inf)
# Combine clean and adversarial data
X_combined = tf.concat([X_train, X_train_adv], axis=0)
y_combined = tf.concat([y_train, y_train], axis=0)
# Retrain the model on the combined dataset
model.fit(X_combined, y_combined, epochs=5, batch_size=32)This code demonstrates how to generate adversarial samples and retrain the model to improve its resilience.
Detection and Filtering of Malicious Data
Another key defense strategy is the detection and filtering of malicious or suspicious data before it reaches the model. This can be achieved through anomaly detection algorithms, statistical tests, or machine learning-based detectors that flag inputs deviating from expected patterns. For example, autoencoders or isolation forests can be used to identify outliers in the input data. In production environments, integrating these detectors as a preprocessing step helps prevent adversarial or poisoned data from influencing the agent’s decisions.
Mechanisms for Robustness Against Manipulation and Attacks
Beyond adversarial training and input filtering, several architectural and algorithmic techniques can enhance the robustness of AI agents. Defensive distillation, for instance, trains the model to produce smoother output distributions, making it harder for attackers to find effective adversarial perturbations. Ensemble methods, where multiple models vote on the final decision, can also reduce vulnerability by making it more difficult for a single attack to succeed. Additionally, regularization techniques such as dropout and weight decay can help prevent overfitting to adversarial patterns.
Example: Defensive Distillation in Python
Defensive distillation is a technique where a model is first trained in the usual way, then a second model is trained to mimic the softened outputs (probabilities) of the first model, rather than the hard labels. This process can make the model less sensitive to small input changes.
python
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Softmax
# Train the original model
model = Sequential([
Dense(64, activation='relu', input_shape=(input_dim,)),
Dense(num_classes, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy')
model.fit(X_train, y_train, epochs=10, batch_size=32)
# Get soft labels (probabilities) with temperature scaling
temperature = 5.0
soft_labels = model.predict(X_train) ** (1 / temperature)
soft_labels = soft_labels / np.sum(soft_labels, axis=1, keepdims=True)
# Train the distilled model on soft labels
distilled_model = Sequential([
Dense(64, activation='relu', input_shape=(input_dim,)),
Dense(num_classes, activation='softmax')
])
distilled_model.compile(optimizer='adam', loss='categorical_crossentropy')
distilled_model.fit(X_train, soft_labels, epochs=10, batch_size=32)This example shows how to implement defensive distillation, which can help mitigate the effectiveness of adversarial attacks.
Self-Healing AI Agents After Adversarial Attacks
Automatic Detection of Model Degradation
A critical aspect of building resilient AI agents is the ability to automatically detect when a model’s performance has degraded, especially after adversarial attacks or data manipulation. Model degradation can manifest as a drop in accuracy, increased error rates, or unexpected behavior in production. To address this, organizations implement continuous monitoring systems that track key performance metrics, such as accuracy, precision, recall, and prediction confidence. When these metrics fall below predefined thresholds, the system can trigger alerts or initiate further investigation.
Modern MLOps platforms, such as Dataiku, IBM Watson OpenScale, and open-source tools like MLflow, provide built-in capabilities for monitoring model health. These platforms can compare recent input data distributions to those seen during training (input drift detection) and evaluate model predictions against ground truth when available. By automating this process, teams can quickly identify when an AI agent is under attack or experiencing data drift, enabling a rapid response.
Retraining and Updating Models in Production
Once model degradation is detected, the next step is to restore the agent’s performance through retraining and updating. Automated retraining pipelines can be set up to periodically or conditionally retrain models using fresh, validated data. This process often involves collecting new labeled data, cleaning and preprocessing it, and then retraining the model from scratch or fine-tuning it on the new data. After retraining, the updated model is validated against a holdout set to ensure it meets performance standards before being redeployed.
Automated retraining can be triggered by various events, such as detection of input drift, performance drops, or the identification of adversarial patterns. MLOps tools like Dataiku and IBM Watson Machine Learning support automated retraining and redeployment workflows, ensuring that AI agents can recover from attacks or adapt to changing environments with minimal human intervention.
Here is a simplified Python example of an automated retraining workflow using scikit-learn and MLflow:
python
import mlflow
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import joblib
# Load new data and previous model
X_train, y_train = ... # Load new training data
X_test, y_test = ... # Load new test data
model = joblib.load("model.pkl")
# Retrain the model
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
# Log the retrained model and metrics
mlflow.sklearn.log_model(model, "retrained_model")
mlflow.log_metric("accuracy", accuracy)
# Save the updated model
joblib.dump(model, "model_retrained.pkl")
# Created/Modified files during execution:
print("model_retrained.pkl")This code demonstrates how to retrain a model, evaluate its performance, and log the results for tracking and reproducibility.
Self-Healing and Adaptive Systems
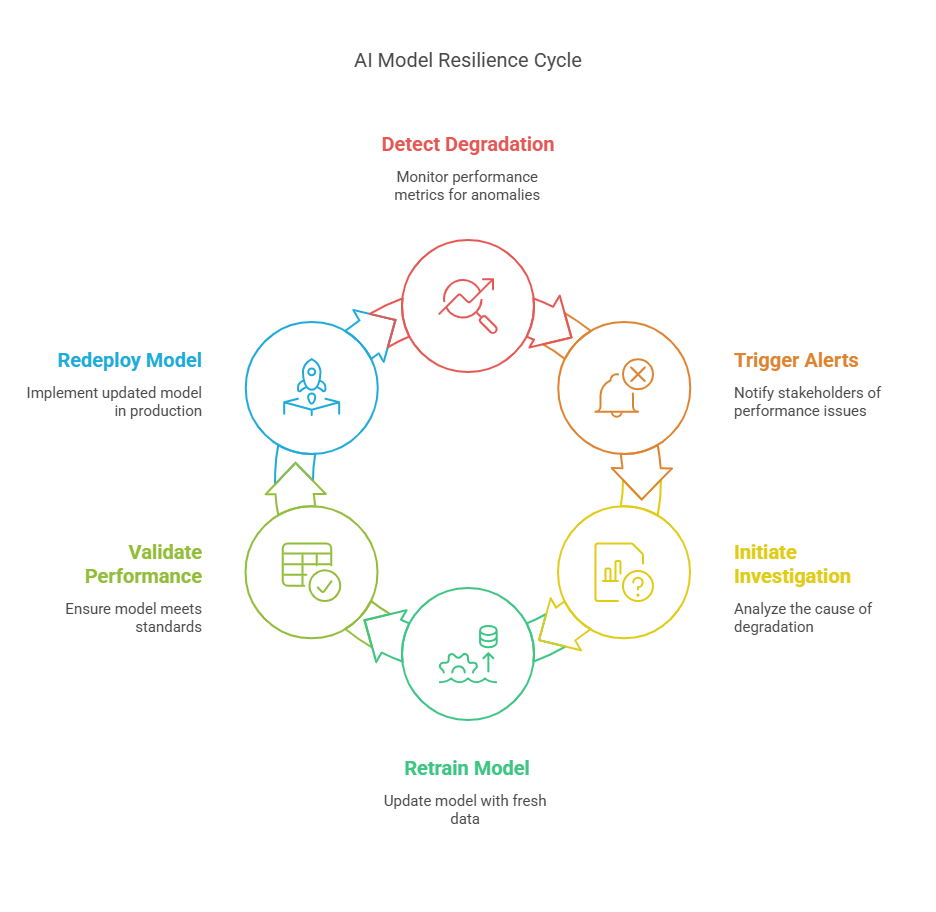
The ultimate goal for resilient AI agents is to achieve self-healing capabilities—systems that can autonomously detect, diagnose, and recover from attacks or failures. Self-healing AI agents combine monitoring, automated retraining, and adaptive mechanisms to maintain optimal performance with minimal human oversight. These systems may use ensemble learning, where multiple models are maintained and the best-performing one is automatically selected, or fallback strategies that switch to a backup model if the primary one is compromised.
Advanced self-healing systems can also incorporate meta-learning, enabling agents to learn how to adapt their own learning processes in response to new threats. For example, an agent might adjust its training strategy or defense mechanisms based on the type and frequency of detected attacks. This level of adaptability is especially important in dynamic environments where adversarial tactics are constantly evolving.
Practical Challenges and Best Practices
Scalability and Performance of Security Solutions
As AI agents are increasingly deployed in large-scale, real-world environments, ensuring that security mechanisms scale efficiently is a major challenge. Defenses such as adversarial training, anomaly detection, and real-time monitoring can be computationally intensive, especially when models are retrained frequently or must process high-throughput data streams. To address this, organizations should leverage scalable MLOps platforms like Dataiku or IBM Watson Machine Learning, which offer features such as distributed training, automated retraining pipelines, and model input drift detection. These platforms help maintain performance and security without overwhelming infrastructure resources.
Integrating Security Mechanisms with MLOps
Modern MLOps practices emphasize the seamless integration of security and monitoring into the machine learning lifecycle. This includes automated validation feedback loops, continuous model evaluation, and dashboard interfaces for monitoring global pipelines. For example, Dataiku provides a unified interface for data connection, wrangling, mining, visualization, deployment, and model monitoring at enterprise scale. Automated retraining and redeployment workflows ensure that models remain robust against new threats, while input drift detection and validation recipes help identify when models are exposed to unfamiliar or adversarial data.
Use Cases and Case Studies
Real-world case studies highlight the importance of robust security practices. In the financial sector, adversarial attacks have been used to bypass fraud detection systems, prompting the adoption of advanced anomaly detection and adversarial training. In healthcare, input data manipulation has led to misdiagnoses by AI-powered diagnostic tools, emphasizing the need for continuous monitoring and validation. Industrial automation and autonomous vehicles also face unique challenges, such as sensor spoofing and data poisoning, which require specialized detection and defense strategies.
Best Practices for Secure and Resilient AI Agents
To build secure and resilient AI agents, organizations should adopt several best practices. First, implement multi-layered defenses that combine adversarial training, anomaly detection, and robust model architectures. Second, automate monitoring and retraining workflows using MLOps platforms to ensure rapid response to emerging threats. Third, maintain comprehensive documentation and governance using tools like IBM Watson OpenScale and AI Factsheets, which support transparency, compliance, and auditability. Finally, foster collaboration between data scientists, engineers, and security experts to ensure that security is embedded throughout the AI lifecycle.
Tools and Libraries Supporting AI Agent Security
Overview of Popular Tools for Detection and Defense
Securing AI agents against adversarial attacks and data manipulation requires a robust set of tools and libraries. Today’s ecosystem offers a variety of open-source and enterprise-grade solutions that help detect, defend, and monitor AI models in production. For adversarial attack detection and defense, libraries such as Adversarial Robustness Toolbox (ART) by IBM, Foolbox, and CleverHans are widely used. These libraries provide implementations of common attack algorithms (like FGSM, PGD, and DeepFool) and defense strategies (such as adversarial training, input preprocessing, and model verification). They allow practitioners to test their models against a range of adversarial scenarios and evaluate the effectiveness of different mitigation techniques.
For anomaly detection and data drift monitoring, tools like scikit-learn, PyOD, and TensorFlow Data Validation offer a suite of algorithms for outlier detection, statistical analysis, and data validation. These can be integrated into machine learning pipelines to flag suspicious inputs or shifts in data distributions that may indicate an ongoing attack or data quality issue.
Frameworks for Adversarial Training and Monitoring
Adversarial training is a key defense mechanism, and several frameworks make it easier to implement in practice. CleverHans and ART both support adversarial training workflows, allowing you to generate adversarial examples and retrain your models for improved robustness. TensorFlow and PyTorch also provide the flexibility to integrate custom adversarial training loops directly into your model training code.
For monitoring and managing models in production, enterprise platforms like IBM Watson OpenScale and Dataiku offer comprehensive solutions. Watson OpenScale enables continuous monitoring of deployed models for fairness, quality, drift, and explainability, with automated alerts and retraining triggers. Dataiku provides a unified interface for data connection, wrangling, machine learning, deployment, and model monitoring at scale. Features such as input drift detection, validation feedback loops, and automated retraining are built-in, making it easier to maintain secure and resilient AI agents in production environments.
Example: Using ART for Adversarial Detection and Defense
Below is a Python example demonstrating how to use the Adversarial Robustness Toolbox (ART) to evaluate a model’s robustness and apply adversarial training:
python
from art.estimators.classification import SklearnClassifier
from art.attacks.evasion import FastGradientMethod
from art.defences.trainer import AdversarialTrainer
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load data and train a simple model
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Wrap the model with ART
classifier = SklearnClassifier(model=model)
# Generate adversarial examples
attack = FastGradientMethod(estimator=classifier, eps=0.2)
X_test_adv = attack.generate(x=X_test)
# Evaluate model on adversarial examples
accuracy = classifier.score(X_test_adv, y_test)
print(f"Accuracy on adversarial examples: {accuracy:.2f}")
# Adversarial training
adv_trainer = AdversarialTrainer(classifier, attacks=attack, ratio=0.5)
adv_trainer.fit(X_train, y_train, nb_epochs=10)This code shows how to generate adversarial examples, evaluate model robustness, and perform adversarial training using ART.
Summary and Future Directions in AI Agent Security
Key Takeaways
Securing AI agents against adversarial attacks and data manipulation is a complex, multi-layered challenge that requires a combination of technical solutions, robust processes, and organizational best practices. The most effective strategies involve integrating detection, defense, and self-healing mechanisms throughout the AI lifecycle. Adversarial training, anomaly detection, and continuous monitoring are essential for building resilient models. Automated retraining and adaptive systems help ensure that AI agents can recover from attacks and maintain high performance in dynamic environments. Leveraging modern MLOps platforms, such as Dataiku and IBM Watson OpenScale, enables organizations to scale these practices efficiently, providing unified interfaces for data management, model deployment, and monitoring at enterprise scale.
Trends and the Future of AI Agent Security
The landscape of AI security is rapidly evolving. As AI agents are deployed in increasingly critical and high-stakes environments, attackers are developing more sophisticated adversarial techniques. In response, the field is moving toward more proactive and automated defenses. Self-healing AI agents, capable of detecting and recovering from attacks with minimal human intervention, are becoming a key area of research and development. The integration of explainability and fairness monitoring, as seen in platforms like IBM Watson OpenScale, is also gaining importance, ensuring that AI systems are not only secure but also transparent and trustworthy.
Another significant trend is the adoption of end-to-end MLOps workflows that embed security and governance at every stage. Automated pipelines for data validation, model retraining, and deployment help organizations respond quickly to new threats and maintain compliance with regulatory requirements. AI governance tools, such as AI Factsheets and OpenPages, are being used to document model metadata, track performance, and ensure transparency across the AI lifecycle.
Recommendations for Practitioners
To stay ahead of emerging threats, practitioners should:
Continuously update their knowledge of adversarial attack techniques and defense strategies.
Invest in scalable MLOps infrastructure that supports automated monitoring, retraining, and governance.
Foster collaboration between data scientists, engineers, and security experts to ensure a holistic approach to AI security.
Prioritize transparency and explainability to build trust with users and stakeholders.
Regularly audit and test AI agents using open-source tools and enterprise platforms to identify vulnerabilities before they can be exploited.
AI Agents: Distributed Systems

