
Introduction to Reinforcement Learning (RL)
Reinforcement Learning (RL) is a branch of machine learning that focuses on training agents to make a sequence of decisions by interacting with an environment. Unlike supervised learning, where models learn from labeled data, RL agents learn by trial and error, receiving feedback in the form of rewards or penalties. This approach is inspired by behavioral psychology, where learning is driven by the consequences of actions.
What is Reinforcement Learning?
Reinforcement Learning is a computational approach where an agent learns to achieve a goal by performing actions and observing the results. The agent interacts with an environment, which provides feedback in the form of rewards (positive or negative). The main objective of the agent is to maximize the cumulative reward over time. RL is particularly useful in situations where it is difficult or expensive to provide explicit supervision, such as robotics, game playing, and autonomous systems.
Key Concepts: Agents, Environments, Actions, Rewards, and Policies
At the core of RL are several fundamental concepts:
Agent: The learner or decision-maker that interacts with the environment.
Environment: The external system with which the agent interacts. It defines the rules, states, and dynamics.
Actions: The set of all possible moves or decisions the agent can make.
States: The current situation or configuration of the environment as perceived by the agent.
Rewards: Scalar feedback signals received after taking actions, indicating the immediate benefit or cost.
Policy: A strategy or mapping from states to actions, guiding the agent’s behavior.
Value Function: An estimate of the expected cumulative reward from a given state or state-action pair.
The agent’s goal is to learn a policy that maximizes the expected sum of rewards, often referred to as the return.
The RL Process: Exploration vs. Exploitation
A central challenge in RL is balancing exploration and exploitation.
Exploration involves trying new actions to discover their effects and potentially find better long-term strategies.
Exploitation means using the current knowledge to choose actions that yield the highest known reward.
Effective RL algorithms must find a balance between these two, ensuring that the agent does not get stuck in suboptimal behaviors due to insufficient exploration.
Applications of Reinforcement Learning
Reinforcement Learning has a wide range of applications across various domains. In robotics, RL enables machines to learn complex tasks such as walking, grasping, or flying by interacting with their environment. In game playing, RL has achieved superhuman performance in games like Go, chess, and video games by learning optimal strategies through self-play. RL is also used in recommendation systems, finance (for portfolio management and trading), autonomous vehicles, and industrial automation.
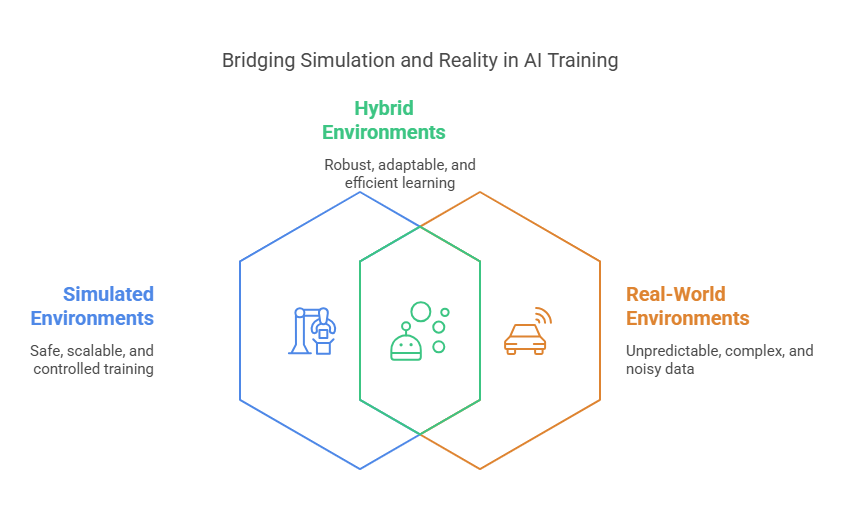
Understanding Hybrid Environments
Hybrid environments are becoming increasingly important in reinforcement learning (RL), especially as AI systems move from research to real-world applications. In this section, we’ll explore what hybrid environments are, their benefits and challenges, and provide practical examples from fields like robotics and autonomous vehicles.
Defining Hybrid Environments: Combining Simulated and Real-World Data
A hybrid environment in reinforcement learning refers to a setup where an agent interacts with both simulated and real-world data. Traditionally, RL agents are trained in either a fully simulated environment (such as a video game or a physics simulator) or directly in the real world. Hybrid environments blend these two approaches, allowing agents to learn from the speed and safety of simulation while also adapting to the unpredictability and complexity of the real world.
For example, a robot might first learn to walk in a simulated environment using a physics engine, and then transfer its knowledge to a real robot for fine-tuning. This combination helps bridge the gap between idealized simulations and the messy, noisy data encountered in reality.
Benefits of Hybrid Environments: Data Efficiency, Safety, and Scalability
Hybrid environments offer several key advantages for reinforcement learning:
Data Efficiency: Simulations can generate large amounts of training data quickly and at low cost. By starting in simulation, agents can learn basic behaviors before being exposed to expensive or limited real-world data.
Safety: Training in simulation allows agents to make mistakes without real-world consequences. This is especially important in domains like robotics or autonomous driving, where errors can be costly or dangerous.
Scalability: Simulated environments can be easily scaled up to run many parallel experiments, accelerating the learning process. Once the agent performs well in simulation, it can be gradually introduced to real-world scenarios.
By leveraging both simulated and real data, hybrid environments enable more robust and adaptable RL agents.
Challenges in Hybrid Environments: Bridging the Reality Gap
Despite their advantages, hybrid environments also present unique challenges. The most significant is the so-called “reality gap”—the differences between simulated and real-world environments. Simulators, no matter how advanced, cannot capture every nuance of the real world. Factors like sensor noise, unmodeled dynamics, and unexpected events can cause agents trained in simulation to perform poorly when deployed in reality.
Bridging this gap requires careful design. Techniques such as domain randomization (where simulation parameters are varied randomly during training) and domain adaptation (where models are fine-tuned on real-world data) are commonly used to help agents generalize better. Additionally, continuous feedback and iterative retraining in the real world are often necessary to achieve reliable performance.
Examples of Hybrid Environments: Robotics, Autonomous Vehicles, and Game Playing
Hybrid environments are widely used in several cutting-edge fields:
Robotics: Robots often learn basic skills like navigation or manipulation in simulation before being tested and refined in the real world. For instance, a robotic arm might practice picking up objects in a virtual environment, then adapt its strategy when faced with real objects of varying shapes and textures.
Autonomous Vehicles: Self-driving cars are trained in simulated traffic scenarios to handle rare or dangerous situations safely. These simulations are then complemented with real-world driving data to ensure the models can cope with real traffic, weather, and road conditions.
Game Playing: In complex games, agents may train in a simulated environment with simplified rules or graphics, then transfer their strategies to more realistic or competitive settings.
Core RL Algorithms for Hybrid Environments
Reinforcement learning (RL) in hybrid environments requires robust algorithms that can handle the complexity of both simulated and real-world data. In this section, we’ll explore the main categories of RL algorithms, their strengths, and how they are applied in hybrid settings.
Model-Based vs. Model-Free RL
RL algorithms are often divided into two broad categories: model-based and model-free.
Model-based RL algorithms attempt to learn a model of the environment’s dynamics. This model predicts the next state and reward given a current state and action. By simulating possible future scenarios, model-based methods can plan ahead and make more data-efficient decisions. This is especially useful in hybrid environments, where real-world data may be limited or expensive to collect. Examples include algorithms like Dyna-Q and Model Predictive Control (MPC).
Model-free RL algorithms, on the other hand, do not attempt to learn the environment’s dynamics. Instead, they learn directly from experience by optimizing a policy or value function. These methods are generally simpler to implement and can be more robust to model inaccuracies, but they often require more data. Popular model-free algorithms include Q-learning, Deep Q-Networks (DQN), and Policy Gradient methods.
Value-Based Methods: Q-Learning, Deep Q-Networks (DQN)
Value-based methods focus on learning a value function, which estimates the expected return (cumulative reward) from each state or state-action pair. The most classic example is Q-learning, where the agent learns a Q-table mapping state-action pairs to values. In complex environments with large or continuous state spaces, Deep Q-Networks (DQN) use neural networks to approximate the Q-function.
Here’s a simple Python example of Q-learning in a discrete environment:
python
import numpy as np
# Initialize Q-table
num_states = 5
num_actions = 2
Q = np.zeros((num_states, num_actions))
# Hyperparameters
alpha = 0.1 # learning rate
gamma = 0.99 # discount factor
epsilon = 0.1 # exploration rate
# Simulate one step of Q-learning
state = 0
action = np.random.choice(num_actions) if np.random.rand() < epsilon else np.argmax(Q[state])
next_state = 1 # Example transition
reward = 1
# Q-learning update
Q[state, action] = Q[state, action] + alpha * (reward + gamma * np.max(Q[next_state]) - Q[state, action])
print(Q)In hybrid environments, DQN and its variants are often used for tasks like robotic control, where the agent is first trained in simulation and then fine-tuned with real-world data.
Policy-Based Methods: REINFORCE, Proximal Policy Optimization (PPO)
Policy-based methods directly optimize the policy—the mapping from states to actions—without explicitly learning a value function. The REINFORCE algorithm is a foundational policy gradient method that updates the policy parameters in the direction that increases expected rewards.
Proximal Policy Optimization (PPO) is a more advanced policy gradient method that improves stability and performance by limiting the size of policy updates. PPO is widely used in both simulated and hybrid environments due to its robustness and ease of implementation.
Here’s a simplified example of a policy gradient update using PyTorch:
python
import torch
import torch.nn as nn
import torch.optim as optim
# Simple policy network
class PolicyNet(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.fc = nn.Linear(state_dim, action_dim)
def forward(self, x):
return torch.softmax(self.fc(x), dim=-1)
policy = PolicyNet(state_dim=4, action_dim=2)
optimizer = optim.Adam(policy.parameters(), lr=0.01)
# Example state and action
state = torch.tensor([[0.1, 0.2, 0.3, 0.4]])
action_probs = policy(state)
action = torch.multinomial(action_probs, num_samples=1)
reward = torch.tensor([1.0])
# Policy gradient update (REINFORCE)
loss = -torch.log(action_probs[0, action]) * reward
optimizer.zero_grad()
loss.backward()
optimizer.step()Actor-Critic Methods: Advantage Actor-Critic (A2C), Asynchronous Advantage Actor-Critic (A3C)
Actor-critic methods combine the strengths of value-based and policy-based approaches. The “actor” learns the policy, while the “critic” estimates the value function. This combination allows for more stable and efficient learning, especially in complex or hybrid environments.
Advantage Actor-Critic (A2C) and Asynchronous Advantage Actor-Critic (A3C) are popular actor-critic algorithms. A2C runs multiple agents in parallel to stabilize training, while A3C uses asynchronous updates from multiple environments, making it well-suited for large-scale simulations and hybrid setups.
Bridging the Reality Gap: Techniques for Simulation-to-Real Transfer
As reinforcement learning (RL) agents move from simulated training to real-world deployment, they often encounter a significant challenge known as the “reality gap.” This gap refers to the differences between the controlled, predictable environment of a simulator and the complex, noisy, and sometimes unpredictable nature of the real world. Successfully bridging this gap is essential for building robust RL systems that perform reliably outside of simulation. In this section, we’ll explore the most effective techniques for simulation-to-real transfer, including domain randomization, domain adaptation, curriculum learning, and meta-learning.
Domain Randomization: Training on Diverse Simulated Environments
Domain randomization is a powerful technique that exposes RL agents to a wide variety of simulated scenarios during training. By randomly varying aspects of the simulation—such as lighting, textures, object positions, physical properties, and sensor noise—the agent learns to generalize its behavior across a broad range of conditions. The goal is to ensure that, when the agent encounters the real world, it treats it as just another variation it has already seen.
For example, in robotics, domain randomization might involve changing the color and shape of objects, altering friction coefficients, or adding random noise to sensor readings. This approach has been successfully used to train robotic arms in simulation and then deploy them directly to real hardware with minimal additional tuning.
Here’s a simple Python snippet illustrating domain randomization in a simulated environment:
python
import random
def randomize_environment(env):
env.light_intensity = random.uniform(0.5, 1.5)
env.object_color = random.choice(['red', 'green', 'blue', 'yellow'])
env.friction = random.uniform(0.8, 1.2)
env.sensor_noise = random.gauss(0, 0.05)
return envBy repeatedly training the agent in these randomized environments, the policy becomes robust to variations it will face in the real world.
Domain Adaptation: Aligning Simulated and Real-World Distributions
While domain randomization prepares agents for a wide range of scenarios, domain adaptation focuses on minimizing the differences between simulated and real-world data distributions. This can involve fine-tuning models on a small amount of real-world data after initial training in simulation, or using techniques like adversarial learning to make simulated data more similar to real data.
A common approach is to use a two-stage process: first, train the agent in simulation; then, collect a limited set of real-world experiences and continue training (fine-tuning) the agent using this new data. This helps the agent adjust to nuances and details that the simulator cannot capture.
Another method is to use adversarial domain adaptation, where a neural network is trained to make features from simulated and real data indistinguishable. This encourages the agent to learn representations that transfer well between domains.
Curriculum Learning: Gradually Increasing Complexity in Simulation
Curriculum learning is inspired by the way humans and animals learn: starting with simple tasks and gradually progressing to more difficult ones. In RL, this means designing a sequence of training environments that increase in complexity over time. The agent first masters basic skills in easy scenarios, then builds on this foundation as it faces more challenging situations.
For example, a robot might first learn to pick up objects in a clutter-free environment, then gradually be exposed to more obstacles, varied object types, and dynamic changes. This staged approach helps the agent develop robust strategies and adapt more effectively when transferred to the real world.
A simple curriculum learning loop in Python might look like this:
python
for level in range(1, max_level + 1):
env = create_environment(difficulty=level)
train_agent(env)By structuring training in this way, agents are less likely to be overwhelmed by complexity and more likely to succeed in real-world deployment.
Meta-Learning: Learning to Adapt Quickly to New Environments
Meta-learning, or “learning to learn,” equips RL agents with the ability to adapt rapidly to new environments or tasks with minimal additional training. In the context of simulation-to-real transfer, meta-learning algorithms train agents on a variety of tasks so that they can quickly adjust their policies when faced with new, unseen situations in the real world.
Popular meta-learning approaches include Model-Agnostic Meta-Learning (MAML), which optimizes agents for fast adaptation, and recurrent neural networks that can update their behavior based on recent experiences. These methods are particularly valuable in hybrid environments where conditions can change unexpectedly.
Meta-learning is an active area of research, and its integration with RL is opening new possibilities for robust, adaptable AI systems.
Best Practices and Tools for RL in Hybrid Environments
Reinforcement learning (RL) in hybrid environments—where agents learn from both simulation and real-world data—requires careful planning, robust tools, and adherence to best practices. This section explores essential strategies and recommended tools to ensure successful RL projects, from experiment tracking and reproducibility to leveraging open-source libraries and frameworks.
Experiment Tracking and Reproducibility
In hybrid RL projects, tracking experiments and ensuring reproducibility are critical. Because agents are trained across different environments and data sources, it’s easy to lose track of which settings, parameters, or code versions led to specific results. To address this, use experiment tracking tools such as MLflow, Weights & Biases, or TensorBoard. These platforms allow you to log hyperparameters, environment configurations, code versions, and performance metrics, making it easier to compare experiments and reproduce results.
For reproducibility, always set random seeds for your environments, neural network libraries (like NumPy, TensorFlow, or PyTorch), and any simulation engines. Document your environment versions and dependencies using tools like requirements.txt or conda environments. This ensures that others (or your future self) can rerun experiments and obtain consistent results.
Open-Source Libraries and Frameworks
The RL community has developed a rich ecosystem of open-source libraries that simplify the implementation and evaluation of RL algorithms in hybrid environments. Some of the most popular and reliable tools include:
Stable Baselines3: A PyTorch-based library offering implementations of state-of-the-art RL algorithms such as PPO, DQN, and A2C. It is widely used for both research and production.
OpenAI Gym: A standard interface for RL environments, supporting both simulated and real-world tasks. Gym makes it easy to swap environments and benchmark algorithms.
RLlib (Ray): A scalable RL library built on Ray, designed for distributed training and large-scale experiments. RLlib supports hybrid workflows and can integrate with real-world data streams.
PyBullet and MuJoCo: Physics engines for simulating robotics and control tasks, often used for training agents before transferring them to real hardware.
Here’s a simple example of using Stable Baselines3 with OpenAI Gym:
python
import gym
from stable_baselines3 import PPO
# Create a simulation environment
env = gym.make("CartPole-v1")
# Initialize the PPO agent
model = PPO("MlpPolicy", env, verbose=1)
# Train the agent
model.learn(total_timesteps=10000)
# Save the trained model
model.save("ppo_cartpole")
# Test the trained agent
obs = env.reset()
for _ in range(1000):
action, _states = model.predict(obs)
obs, reward, done, info = env.step(action)
env.render()
if done:
obs = env.reset()
env.close()Data Management and Versioning
Hybrid RL projects often involve large and diverse datasets from both simulation and real-world sources. Managing these datasets effectively is crucial. Use data versioning tools like DVC (Data Version Control) or LakeFS to track changes, share datasets, and ensure consistency across experiments. Store metadata about how and when data was collected, and document any preprocessing steps.
Continuous Integration and Automated Testing
As RL projects grow in complexity, automated testing and continuous integration (CI) become essential. Set up CI pipelines to automatically run unit tests, integration tests, and environment checks whenever code is updated. This helps catch bugs early and ensures that changes do not break existing functionality. Tools like GitHub Actions, GitLab CI, or Jenkins can be integrated with your code repository for seamless automation.
Collaboration and Documentation
Hybrid RL projects often involve multidisciplinary teams, including researchers, engineers, and domain experts. Maintain clear and up-to-date documentation for your code, experiments, and environment configurations. Use collaborative platforms like GitHub or GitLab for version control and code reviews. Well-documented code and shared experiment logs make it easier for team members to contribute and onboard new collaborators.
Case Studies: Reinforcement Learning in Hybrid Environments
Hybrid environments—where reinforcement learning (RL) agents learn from both simulation and real-world data—are not just theoretical concepts. They are actively used in a variety of industries to solve complex, high-stakes problems. In this section, we’ll explore real-world case studies that demonstrate how hybrid RL environments are applied in robotics, autonomous vehicles, and industrial automation, highlighting the practical benefits and lessons learned.
Robotics: Sim-to-Real Transfer for Manipulation Tasks
Robotics is one of the most prominent fields leveraging hybrid RL environments. Training robots directly in the real world is often slow, expensive, and risky. Instead, researchers and engineers use physics-based simulators to teach robots basic skills, such as grasping, stacking, or assembling objects. Once the agent achieves high performance in simulation, its policy is transferred to a real robot for further fine-tuning.
A well-known example is OpenAI’s work on robotic hand manipulation. The team trained a robotic hand to solve a Rubik’s Cube using domain randomization in simulation, exposing the agent to a wide range of physical parameters and visual conditions. When the policy was deployed on a real robot, it was able to adapt to the unpredictable dynamics of the real world with minimal additional training. This approach dramatically reduced the cost and risk of real-world experimentation.
Here’s a simplified Python snippet showing how you might structure a sim-to-real workflow for a robotic arm using OpenAI Gym and Stable Baselines3:
python
import gym
from stable_baselines3 import PPO
# Simulated environment
sim_env = gym.make("FetchPickAndPlace-v1")
model = PPO("MlpPolicy", sim_env, verbose=1)
model.learn(total_timesteps=100000)
# Save the trained model
model.save("ppo_fetch_sim")
# Later, load the model and fine-tune on real-world data
# real_env = RealRobotEnv() # Custom wrapper for real robot
# model.set_env(real_env)
# model.learn(total_timesteps=10000)This workflow allows for rapid iteration in simulation, followed by targeted adaptation in the real world.
Autonomous Vehicles: Safe Policy Learning with Hybrid Data
Autonomous vehicles (AVs) must operate safely in highly dynamic and unpredictable environments. Training AVs solely in the real world is impractical due to safety concerns and the rarity of critical edge cases. Hybrid RL environments address this by combining large-scale simulation—where millions of driving scenarios can be generated and tested—with real-world driving data for validation and fine-tuning.
For example, companies like Waymo and Tesla use simulated environments to expose their AVs to rare but dangerous situations, such as sudden pedestrian crossings or extreme weather. The policies learned in simulation are then validated and adjusted using real-world sensor data, ensuring that the vehicle can handle both common and exceptional scenarios.
A typical hybrid workflow might involve:
Training a policy in a high-fidelity driving simulator.
Collecting real-world driving logs and using them to identify gaps or failure cases.
Fine-tuning the policy on real-world data, possibly using techniques like domain adaptation or imitation learning.
This approach accelerates development while maintaining safety and reliability.
Industrial Automation: Optimizing Processes with Hybrid RL
In industrial automation, RL agents are used to optimize processes such as energy management, production scheduling, and quality control. Simulators model the physical processes, allowing agents to experiment and learn optimal strategies without disrupting actual operations. Once a promising policy is found, it is gradually introduced into the real system, where it is monitored and refined.
A case study from the energy sector involves using RL to optimize the operation of a smart grid. The agent is first trained in a simulated environment that models energy demand, supply, and pricing. After achieving strong performance, the policy is deployed in a real-world pilot, where it continues to learn from live data and adapts to unforeseen events, such as equipment failures or market fluctuations.
Lessons Learned and Best Practices
These case studies reveal several key lessons for practitioners:
Start in simulation, but plan for real-world adaptation: Simulation accelerates learning and reduces risk, but real-world fine-tuning is essential for robust performance.
Use domain randomization and adaptation: Exposing agents to diverse simulated conditions and adapting to real data helps bridge the reality gap.
Monitor and evaluate continuously: Even after deployment, RL agents should be monitored for unexpected behaviors and retrained as needed.
Leverage open-source tools and frameworks: Libraries like OpenAI Gym, Stable Baselines3, and custom wrappers for real-world systems streamline the hybrid RL workflow.
The Future of Reinforcement Learning in Hybrid Environments
Reinforcement learning (RL) in hybrid environments is rapidly evolving, driven by new research, emerging technologies, and the growing demand for robust AI systems that can operate seamlessly between simulation and the real world. In this section, we’ll explore the latest trends, key challenges, and promising directions for the future of RL in hybrid settings.
Latest Trends: Generative AI, Large-Scale Simulation, and Automation
One of the most significant trends is the integration of generative AI with RL. Generative models, such as large language models (LLMs) and diffusion models, are increasingly used to create more realistic and diverse simulated environments. This enables RL agents to train in scenarios that closely mimic real-world complexity, improving their ability to generalize and transfer skills.
Another major trend is the use of large-scale, cloud-based simulation. By leveraging clusters of GPUs or cloud infrastructure, organizations can run thousands of simulations in parallel, dramatically accelerating the training process. This scalability is essential for developing agents that must handle rare events or edge cases, especially in fields like autonomous vehicles and robotics.
Automation is also becoming central to hybrid RL workflows. Tools for automated hyperparameter tuning, neural architecture search, and experiment management are streamlining the development process. These advances reduce manual effort, speed up iteration cycles, and help teams focus on higher-level problem-solving.
Challenges: Data Efficiency, Safety, and Real-World Adaptation
Despite these advances, several challenges remain. Data efficiency is a persistent issue—collecting real-world data is often expensive or risky, so algorithms that can learn effectively from limited real-world experience are in high demand. Techniques like model-based RL, meta-learning, and transfer learning are being actively researched to address this.
Safety is another critical concern. RL agents deployed in the real world must be robust to unexpected situations and avoid unsafe behaviors. This requires not only better training methods but also rigorous testing, monitoring, and fail-safe mechanisms.
Adapting to real-world changes is also challenging. Hybrid environments are dynamic, and agents must be able to handle shifts in data distributions, sensor noise, and evolving operational conditions. Continuous learning and online adaptation are promising approaches, but they require careful design to avoid catastrophic forgetting or instability.
Promising Directions: Self-Supervised Learning, Continual Learning, and Human-in-the-Loop
Looking ahead, several research directions are poised to shape the future of RL in hybrid environments. Self-supervised learning, where agents learn useful representations from unlabeled data, can significantly reduce the need for manual annotation and accelerate learning in both simulation and reality.
Continual learning is another exciting area. Agents that can learn incrementally, without forgetting previous knowledge, will be better equipped to operate in changing environments and adapt to new tasks over time.
Finally, human-in-the-loop approaches are gaining traction. By incorporating human feedback, guidance, or intervention, RL agents can learn more safely and efficiently, especially in high-stakes applications like healthcare, manufacturing, and autonomous systems.
Summary and Key Takeaways
As we conclude our exploration of reinforcement learning (RL) in hybrid environments, it’s important to reflect on the main lessons, best practices, and future directions that can guide both practitioners and researchers. This section summarizes the most important points discussed throughout the series and offers actionable advice for anyone looking to succeed with RL in hybrid settings.
Main Lessons Learned
Hybrid environments—where RL agents learn from both simulation and real-world data—offer a powerful approach to developing robust, adaptable AI systems. The key advantage is the ability to leverage the speed, safety, and flexibility of simulation while grounding learning in the complexity and unpredictability of the real world. This combination accelerates development, reduces risk, and enables agents to generalize better across diverse scenarios.
We’ve seen that bridging the “reality gap” is a central challenge. Techniques such as domain randomization, domain adaptation, curriculum learning, and meta-learning are essential for ensuring that policies trained in simulation transfer effectively to real-world tasks. Each method has its strengths, and often the best results come from combining several approaches.
Best Practices for Practitioners
To maximize the benefits of RL in hybrid environments, practitioners should focus on several best practices. First, rigorous experiment tracking and reproducibility are crucial—use tools like MLflow, Weights & Biases, or TensorBoard to log experiments, and always set random seeds for consistency. Second, leverage open-source libraries and frameworks such as Stable Baselines3, OpenAI Gym, and RLlib to accelerate development and ensure access to state-of-the-art algorithms.
Effective data management is also vital. Use data versioning tools like DVC to keep track of datasets from both simulation and real-world sources, and document all preprocessing steps. Automated testing and continuous integration help maintain code quality and catch issues early, while clear documentation and collaboration platforms like GitHub foster teamwork and knowledge sharing.
Future Directions and Open Questions
The field of RL in hybrid environments is evolving rapidly. Looking ahead, we can expect deeper integration of generative AI for creating richer simulations, more scalable and automated training pipelines, and advances in self-supervised and continual learning. Human-in-the-loop systems will play a growing role in ensuring safety and accelerating adaptation.
However, open questions remain. How can we further improve data efficiency, especially when real-world data is scarce or expensive? What are the best ways to ensure safety and reliability as agents become more autonomous? How can we design systems that adapt gracefully to changing environments and requirements?
Final Thoughts
Reinforcement learning in hybrid environments is already transforming fields like robotics, autonomous vehicles, and industrial automation. By combining the strengths of simulation and real-world data, and by following best practices in experiment management, data handling, and collaboration, practitioners can build AI systems that are both innovative and reliable.
Further Resources and Learning Paths
Reinforcement learning (RL) in hybrid environments is a rapidly evolving field, and staying up to date with the latest tools, research, and best practices is essential for both beginners and experienced practitioners. In this section, you’ll find curated resources and learning paths to help you deepen your understanding, expand your skills, and connect with the broader RL community.
Recommended Books and Online Courses
To build a strong foundation in RL and its applications, start with authoritative books and structured online courses. Some of the most respected books include “Reinforcement Learning: An Introduction” by Richard S. Sutton and Andrew G. Barto, which covers the theoretical underpinnings and practical algorithms of RL, and “Deep Reinforcement Learning Hands-On” by Maxim Lapan, which provides hands-on projects and code examples using Python and PyTorch.
For online learning, platforms like Coursera, edX, and Udacity offer comprehensive RL courses. The “Deep Reinforcement Learning Specialization” by the University of Alberta (Coursera) and “Deep Reinforcement Learning Nanodegree” by Udacity are excellent starting points. These courses often include video lectures, quizzes, and practical assignments to reinforce your learning.
Open-Source Libraries and Frameworks
Experimenting with real code is crucial for mastering RL in hybrid environments. Popular open-source libraries such as Stable Baselines3, RLlib (Ray), and OpenAI Gym provide robust implementations of RL algorithms and a wide variety of simulation environments. These tools make it easy to prototype, test, and benchmark RL agents.
For robotics and sim-to-real projects, consider exploring PyBullet, MuJoCo, and Isaac Gym, which offer high-fidelity physics simulations. If you’re interested in distributed or large-scale RL, Ray and RLlib are designed for scalability and integration with cloud infrastructure.
Research Papers and Conferences
To stay at the cutting edge, regularly read research papers from top conferences such as NeurIPS, ICML, ICLR, and AAAI. These venues publish the latest advances in RL algorithms, sim-to-real transfer, meta-learning, and hybrid environment applications. ArXiv.org is a valuable resource for preprints and open-access papers.
Following the proceedings of workshops and special sessions on RL in robotics, autonomous systems, and industrial AI can also provide insights into emerging trends and real-world challenges.
Community Forums and Online Groups
Engaging with the RL community can accelerate your learning and help you solve practical problems. Join forums like Stack Overflow, Reddit’s r/reinforcementlearning, and the AI Alignment Forum to ask questions, share experiences, and discuss new ideas. Many open-source projects have active GitHub repositories and Discord or Slack channels where you can interact with developers and contributors.
Participating in online competitions, such as those hosted on Kaggle or OpenAI’s Spinning Up, is another great way to test your skills and learn from others.
Practical Projects and Next Steps
The best way to solidify your knowledge is through hands-on projects. Start by replicating classic RL experiments, such as training agents to play Atari games or control simulated robots. Then, move on to more complex hybrid scenarios, like sim-to-real transfer in robotics or RL for industrial process optimization.
Appendix: Python Code Examples and Exercises
To help you solidify your understanding of reinforcement learning (RL) in hybrid environments and Python programming in general, this appendix provides practical code examples and exercises. These resources are designed to reinforce key concepts, encourage experimentation, and support hands-on learning.
Example 1: Basic Python Class and Inheritance
Understanding object-oriented programming (OOP) is essential for building scalable RL systems. Here’s a simple example inspired by the classic “pizza robot” scenario from Learning Python:
python
class Employee:
def __init__(self, name, salary=0):
self.name = name
self.salary = salary
def give_raise(self, percent):
self.salary += self.salary * percent
def work(self):
print(self.name, "does stuff")
def __repr__(self):
return f"<Employee: name={self.name}, salary={self.salary}>"
class Chef(Employee):
def __init__(self, name):
super().__init__(name, 50000)
def work(self):
print(self.name, "makes food")
class Server(Employee):
def __init__(self, name):
super().__init__(name, 40000)
def work(self):
print(self.name, "interfaces with customer")
class PizzaRobot(Chef):
def work(self):
print(self.name, "makes pizza")
if __name__ == "__main__":
bob = PizzaRobot('Bob')
print(bob)
bob.work()
bob.give_raise(0.20)
print(bob)
for klass in (Employee, Chef, Server, PizzaRobot):
obj = klass(klass.__name__)
obj.work()This code demonstrates inheritance, method overriding, and the use of super(). Try running and modifying it to see how class hierarchies work in Python.
Example 2: Simple Reinforcement Learning Loop
Below is a minimal RL loop using Q-learning for a discrete environment. This is a foundation for more advanced RL projects:
python
import numpy as np
num_states = 5
num_actions = 2
Q = np.zeros((num_states, num_actions))
alpha = 0.1
gamma = 0.99
epsilon = 0.1
state = 0
for episode in range(100):
action = np.random.choice(num_actions) if np.random.rand() < epsilon else np.argmax(Q[state])
next_state = (state + 1) % num_states
reward = 1 if next_state == 0 else 0
Q[state, action] += alpha * (reward + gamma * np.max(Q[next_state]) - Q[state, action])
state = next_state
print(Q)This code illustrates the core of value-based RL. Experiment with the parameters and logic to see how learning changes.
Example 3: String Manipulation and Formatting
String operations are fundamental in Python, especially for logging, reporting, and data preprocessing in ML workflows. Here’s a quick example:
python
name = "Ada"
course = "Python Programming"
instructor = "Dr. Smith"
message = "Dear {}, you are enrolled in {} with {}.".format(name, course, instructor)
print(message)You can also use f-strings for more concise formatting:
python
print(f"Dear {name}, you are enrolled in {course} with {instructor}.")Exercise 1: Implement a Simple Tip Calculator
Write a Python program that asks the user for the bill amount, tip percentage, and number of people, then calculates and prints the tip per person and total per person, formatted to two decimal places.
python
bill = float(input("Enter bill amount: "))
tip_percent = float(input("Percentage to tip: "))
num_people = int(input("Number of people: "))
tip_amount = bill * tip_percent / 100
total_amount = bill + tip_amount
tip_per_person = tip_amount / num_people
total_per_person = total_amount / num_people
print(f"\nTip amount: ${tip_amount:.2f}")
print(f"Total amount: ${total_amount:.2f}")
print(f"Tip per person: ${tip_per_person:.2f}")
print(f"Total per person: ${total_per_person:.2f}")Exercise 2: Create a Class Hierarchy for a Zoo
Model a simple zoo animal hierarchy using inheritance. Each animal should have a speak method that prints a unique message. Add a reply method in the base class that calls self.speak().
python
class Animal:
def reply(self):
self.speak()
class Mammal(Animal):
def speak(self):
print("Generic mammal sound")
class Cat(Mammal):
def speak(self):
print("meow")
class Primate(Mammal):
def speak(self):
print("Hello world!")
class Hacker(Primate):
pass # Inherits speak from Primate
# Test
spot = Cat()
spot.reply() # Output: meow
data = Hacker()
data.reply() # Output: Hello world!Exercise 3: Multi-line String Formatting
Write a program that prints five quotes, each on a new line, using multi-line strings and proper formatting.
python
quotes = [
"“If you're talking about Java in particular, Python is about the best fit you can get amongst all the other languages.”",
"“The second stream of material that is going to come out of this project is a programming environment and a set of programming tools where we really want to focus again on the needs of the newbie.”",
"“I have this hope that there is a better way. Higher-level tools that actually let you see the structure of the software more clearly will be of tremendous value.”",
"“Now, it's my belief that Python is a lot easier to teach to students than C or C++ or Java at the same time because all the details of the languages are so much harder.”",
"“I would guess that the decision to create a small special purpose language or use an existing general purpose language is one of the toughest decisions that anyone facing the need for a new language must make.”"
]
for quote in quotes:
print(quote)(FAQ) About Python and Reinforcement Learning
This section addresses some of the most common questions that beginners and intermediate users have about Python programming and reinforcement learning (RL), especially in the context of hybrid environments. Drawing from both foundational resources like Learning Python and Introduction to Python Programming, as well as practical experience, these answers are designed to clarify key concepts and help you avoid common pitfalls.
What are the main reasons to use Python for AI and RL?
Python is widely chosen for AI and RL because of its high software quality, developer productivity, portability, extensive support libraries, component integration, and the sheer enjoyment of coding in it. Its readable syntax, large community, and wealth of open-source libraries (like NumPy, TensorFlow, PyTorch, and Stable Baselines3) make it ideal for both rapid prototyping and production-level projects. Python’s object-oriented features also make it easy to model complex systems, which is essential in RL.
How do I avoid common coding mistakes in Python?
Some frequent mistakes include forgetting colons at the end of compound statements, inconsistent indentation (mixing tabs and spaces), and not starting top-level code in column 1. Always use consistent indentation, remember to end if, for, and while statements with a colon, and use blank lines carefully at the interactive prompt. Following PEP 8, Python’s style guide, will help you write clean and maintainable code.
What is the difference between inheritance and composition in Python classes?
Inheritance allows you to create a new class that reuses, extends, or modifies the behavior of another class. For example, a PizzaRobot class can inherit from a Chef class, gaining all its methods and attributes. Composition, on the other hand, means building classes that contain instances of other classes, using their functionality as needed. Both are powerful OOP techniques—inheritance is great for code reuse, while composition is ideal for building complex systems from simpler components.
How do I format strings and numbers in Python?
Python offers several ways to format strings, including the format() method and f-strings (since Python 3.6). For example, you can write:
python
name = "Ada"
score = 95.1234
print(f"Student {name} scored {score:.2f} points.")This will output: Student Ada scored 95.12 points.
You can also use named or numbered replacement fields with format(), and specify alignment, width, and precision for both strings and numbers.
What are the best practices for experiment tracking and reproducibility in RL projects?
Always log your experiments using tools like MLflow, Weights & Biases, or TensorBoard. Set random seeds for all libraries and environments to ensure reproducibility. Document your code, dependencies, and environment versions using requirements.txt or conda environments. Version your datasets and code with tools like Git and DVC.
How do I split and join strings in Python?
To split a string into a list of substrings, use the split() method. For example, „a b c”.split() returns [’a’, 'b’, 'c’]. To join a list of strings into a single string, use the join() method: „,”.join([’a’, 'b’, 'c’]) returns 'a,b,c’.
What is the typical workflow for a machine learning or RL project?
A standard workflow includes: defining the project and goals, collecting and preprocessing data, splitting data into training, validation, and test sets, training and refining models, evaluating performance, and deploying to production. In RL, you may also include simulation-to-real transfer, continuous monitoring, and retraining as part of the lifecycle.
How do I handle exceptions and errors in Python?
Python uses try/except blocks to catch and handle exceptions. For example:
python
try:
result = 10 / 0
except ZeroDivisionError:
print("You can't divide by zero!")This prevents your program from crashing and allows you to handle errors gracefully.
What are some good resources for learning more about Python and RL?
Some recommended books include Learning Python by Mark Lutz and Reinforcement Learning: An Introduction by Sutton and Barto. For online courses, platforms like Coursera, edX, and Udacity offer excellent RL and Python programming tracks. The official Python documentation (https://docs.python.org/3/) and community forums like Stack Overflow and Reddit’s r/learnpython are also invaluable.
How can I practice and improve my Python skills?
Work through exercises and projects from books and online courses. Try coding classic problems, such as building a tip calculator, formatting strings, or implementing a simple RL agent. Participate in coding challenges on platforms like LeetCode, HackerRank, or Kaggle. Reviewing and contributing to open-source projects on GitHub is also a great way to learn from real-world code.
Building AI Agents: A Practical Approach to Python
Debugging with AI: How Agents Make Error Detection Easier
The AI Agent Revolution: Changing the Way We Develop Software

