
Introduction to MLOps in Practice
MLOps, or Machine Learning Operations, is a set of practices, tools, and processes that enable the effective deployment, management, and scaling of machine learning models in production environments. Modern organizations are increasingly leveraging artificial intelligence to solve key business problems, but building a model is only the beginning. The real challenge lies in automation, reliability, and scalability of AI model deployments—and this is where MLOps plays a crucial role.
What is MLOps and Why is it Crucial for AI?
MLOps is an approach inspired by DevOps practices, bringing together data science, engineering, and IT operations teams to ensure a smooth workflow from experimentation to production. With MLOps, it is possible not only to deploy models quickly, but also to monitor them, automate updates, manage versions, and ensure compliance with business and regulatory requirements.
In practice, MLOps allows organizations to:
shorten the time from idea to model deployment (time to market),
minimize the risk of errors and failures in production environments,
ensure repeatability and auditability of processes,
better manage knowledge and documentation within the team.
As highlighted in the „Complete Guide to MLOps” and Dataiku’s „Introducing MLOps,” MLOps is the standardization and streamlining of the machine learning lifecycle. It addresses the growing complexity of managing multiple models, dependencies, and the need for collaboration across business, data science, and IT teams.
Challenges of Deploying AI Models at Scale
Deploying a single AI model may seem simple, but in reality, organizations often need to manage dozens or hundreds of models operating on different data, in various environments, and requiring regular updates. The main challenges include:
Data variability: Input data can change, leading to data drift and reduced prediction quality. As noted in „practical-mlops-ebook.pdf,” constant monitoring and retraining are required to maintain model performance.
Manual, non-repeatable processes: Lack of automation makes it difficult to reproduce results and replicate successes.
Lack of standardization: Different teams may use different tools and practices, making collaboration and model maintenance harder.
Risk management: AI models can generate errors with real business impact, so monitoring and rapid response to issues are essential.
Additionally, as described in the Dataiku guide, MLOps helps mitigate risks, ensures responsible AI, and supports scaling by providing frameworks for versioning, testing, and automation.
The Role of Automation and Scaling in Modern Organizations
Automating MLOps processes enables fast and safe model deployment, updates, and real-time monitoring. This allows teams to focus on developing new solutions instead of manual infrastructure and process management. Scaling AI deployments makes it possible to handle a growing number of models and users without sacrificing quality or performance.
For example, automating data and model pipelines allows for:
automatic ingestion and processing of new data,
periodic training and testing of models,
deploying the best model versions to production,
real-time monitoring of prediction performance and quality.
Modern MLOps tools, such as Dataiku, IBM Cloud Pak for Data, and Kubernetes-based platforms, enable the creation of scalable, automated environments that support the entire AI model lifecycle—from experimentation to production. As described in the „Complete Guide to MLOps,” these tools help break down silos between data science and operations, standardize processes, and ensure compliance and auditability.
The AI/ML Model Lifecycle
Deploying an effective AI model requires not only advanced algorithms but also a well-organized lifecycle that covers all stages—from data acquisition to monitoring the deployed model. Understanding and standardizing this process is the foundation of efficient MLOps. Below, we discuss the key phases of the AI/ML model lifecycle, based on best practices from IBM, Dataiku, Run:ai, and other industry guides.
2.1 Data Collection and Preparation
Every AI project starts with data. Collecting relevant data, cleaning, transforming, and enriching it are crucial steps that directly impact the quality of the final model. In practice, this means integrating data from various sources (databases, APIs, files), removing missing values and anomalies, and performing feature engineering to extract the most important information from the data.
Python example – basic data validation and preparation:
python
import pandas as pd
# Load data
data = pd.read_csv('data.csv')
# Remove missing values
data = data.dropna()
# Feature engineering: create a new feature based on existing ones
data['feature_sum'] = data['feature1'] + data['feature2']
# Preview prepared data
print(data.head())
# Created/Modified files during execution:
print("data.csv")According to IBM’s MLOps Guide and Dataiku’s documentation, tools like DataStage and Data Refinery can automate and standardize these processes, ensuring data quality and traceability.
2.2 Model Building, Training, and Testing
After preparing the data, the next phase is experimenting with different algorithms and model architectures. It is essential to split the data into training, validation, and test sets, then train models, optimize hyperparameters, and evaluate their effectiveness using selected metrics (such as accuracy, precision, recall).
Python example – training and testing a model:
python
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# Split data
X = data.drop('target', axis=1)
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Evaluate model
accuracy = model.score(X_test, y_test)
print(f"Test accuracy: {accuracy:.2f}")As described in the IBM and Run:ai guides, platforms like Watson Machine Learning and AutoAI can automate model training, hyperparameter optimization, and even model selection, accelerating the entire process.
2.3 Model Validation, Deployment, and Monitoring
Once the best model is selected, it is validated on new, unseen data and deployed to the production environment. Modern MLOps platforms enable automation of this process, for example through CI/CD pipelines, model registries, and tools for real-time performance and prediction quality monitoring.
Monitoring includes detecting data drift, drops in prediction quality, or non-compliance with business requirements. If necessary, the model can be automatically retrained or rolled back. IBM Watson OpenScale, for example, allows you to monitor fairness, quality, drift, and explainability of models in production.
2.4 Version Control and Experiment Reproducibility
One of the biggest challenges in MLOps is ensuring experiment reproducibility and tracking versions of data, code, and models. Tools such as MLflow, DVC, or cloud-based model registries allow for automatic saving of metadata, training parameters, results, and model artifacts. This makes it possible to quickly reproduce any experiment, conduct audits, and ensure regulatory compliance.
As highlighted in the „practical-mlops-ebook.pdf,” versioning and change tracking are essential for collaboration, rollback, and A/B testing, and should be managed similarly to code in software engineering.
Automation Strategies in MLOps
Automation is the foundation of modern AI deployments—it not only accelerates the model lifecycle but also increases reliability, repeatability, and security. In practical MLOps, automation covers both data processing and the training, testing, deployment, and monitoring of models. Below, we present the key automation strategies in MLOps, based on best practices and solutions described in IBM, Dataiku, Run:ai, and other industry guides.
3.1 Automating Data and Model Pipelines
Automated pipelines are sequences of tasks that execute each stage of the model lifecycle—from data ingestion and processing, through training, to deployment and monitoring. Tools like Watson Pipelines, Apache Airflow, and Dataiku allow you to build pipelines visually or with code, making it easier to manage complex workflows and ensure repeatability.
For example, with IBM Watson Pipelines, you can assemble a pipeline that collects data, runs scripts, trains models, stores results, and deploys assets. The pipeline editor lets teams collaborate, schedule jobs, and monitor the entire process from a single dashboard. This approach reduces manual intervention, speeds up iteration, and helps maintain consistency across projects.
3.2 CI/CD for Machine Learning Models
Continuous Integration and Continuous Delivery (CI/CD) are essential for automating the testing, validation, and deployment of machine learning models. In MLOps, CI/CD pipelines automatically trigger model retraining, testing, and deployment whenever new data or code changes are introduced. This ensures that models are always up-to-date and that any issues are detected early.
Popular tools for CI/CD in MLOps include Jenkins, GitHub Actions, GitLab CI, and cloud-native solutions integrated with platforms like IBM Cloud Pak for Data. These tools support version control, automated testing, and deployment workflows, making it easier to manage the full lifecycle of AI assets.
3.3 Automated Model Testing, Validation, and Retraining
Automated testing and validation are critical for ensuring that models perform as expected before and after deployment. This includes running unit tests on data preprocessing scripts, validating model accuracy on holdout datasets, and checking for data drift or bias. Automated retraining pipelines can be set up to periodically retrain models when new data becomes available or when performance drops below a defined threshold.
For example, IBM Watson OpenScale provides tools to monitor deployed models for fairness, quality, drift, and explainability. If a model’s performance degrades or bias is detected, automated workflows can trigger retraining or rollback to a previous version.
3.4 Infrastructure as Code (IaC) and Resource Orchestration
Infrastructure as Code (IaC) allows teams to define and manage computing resources (such as servers, storage, and networking) using code. This makes it possible to automate the provisioning, scaling, and management of infrastructure required for machine learning workloads. Tools like Terraform, Ansible, and Kubernetes are widely used for IaC and orchestration in MLOps.
With Kubernetes, for example, you can automate the deployment and scaling of containerized machine learning workloads, ensuring efficient use of resources and high availability. Run:ai extends these capabilities by providing advanced GPU scheduling, dynamic resource allocation, and support for distributed training, further optimizing infrastructure for AI projects.
3.5 AutoML and Advanced Automation
AutoML (Automated Machine Learning) platforms, such as IBM AutoAI, automate many of the repetitive and time-consuming tasks in model development. AutoML can handle data preprocessing, feature engineering, model selection, and hyperparameter optimization, allowing data scientists to focus on higher-level problem-solving.
AutoML tools are especially valuable for organizations with limited machine learning expertise, as they lower the barrier to entry and accelerate the development of high-quality models. They can be integrated into end-to-end MLOps pipelines, complementing custom workflows and supporting rapid prototyping.
Example: Automated Model Training Pipeline in Python
Below is a simplified example of an automated model training pipeline using Python and scikit-learn. In practice, such pipelines can be orchestrated with tools like Airflow or Watson Pipelines for full automation.
python
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import joblib
# Load and preprocess data
data = pd.read_csv('data.csv')
data = data.dropna()
X = data.drop('target', axis=1)
y = data['target']
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Evaluate and save model
accuracy = model.score(X_test, y_test)
print(f"Test accuracy: {accuracy:.2f}")
joblib.dump(model, 'rf_model.pkl')
# Created/Modified files during execution:
print("rf_model.pkl")Tools and Technologies for MLOps Automation
Modern MLOps relies on a robust ecosystem of tools and technologies that enable automation, scalability, and reliability throughout the AI lifecycle. From orchestration and model versioning to monitoring and automated testing, the right toolchain is essential for efficient, enterprise-grade machine learning operations. Below, we explore the most important categories of MLOps tools, referencing best practices and solutions from IBM, Dataiku, Run:ai, and other industry leaders.
4.1 Orchestration Tools (e.g., Kubernetes, Apache Airflow)
Orchestration tools are the backbone of automated MLOps workflows. They manage the execution of complex pipelines, coordinate resources, and ensure that each step in the machine learning lifecycle—from data ingestion to model deployment—runs smoothly and reliably.
Kubernetes is the industry standard for container orchestration, enabling scalable deployment and management of containerized machine learning workloads. With Kubernetes, teams can automate the scaling, scheduling, and health monitoring of AI services, making it easier to run distributed training jobs and serve models in production.
Apache Airflow is a popular workflow orchestration tool that allows users to define, schedule, and monitor complex data and ML pipelines as code. Airflow’s DAG (Directed Acyclic Graph) structure makes it easy to visualize dependencies and automate multi-step processes, such as data preprocessing, model training, and batch inference.
IBM Watson Pipelines provides a visual and code-based interface for building, running, and monitoring end-to-end AI workflows. It integrates seamlessly with other IBM Cloud Pak for Data services, supporting collaboration across data science, engineering, and operations teams.
4.2 Model Registry and Versioning Systems
Model registries are essential for tracking, versioning, and managing machine learning models throughout their lifecycle. They provide a central repository where models, metadata, and artifacts can be stored, compared, and deployed.
MLflow Model Registry is an open-source solution that allows teams to register models, manage model stages (e.g., staging, production), and track lineage and metadata. It supports integration with popular ML frameworks and CI/CD tools, enabling automated promotion and rollback of models.
IBM Watson Machine Learning includes a built-in model registry that supports versioning, approval workflows, and integration with governance tools like Watson OpenScale and AI Factsheets. This ensures that only validated and compliant models are deployed to production.
Model registries also facilitate collaboration, reproducibility, and auditability, which are critical for regulated industries and large-scale AI deployments.
4.3 Monitoring and Alerting Platforms
Continuous monitoring is vital to ensure that deployed models maintain high performance, fairness, and compliance over time. Monitoring platforms track key metrics such as accuracy, drift, bias, and resource utilization, and can trigger alerts or automated actions when issues are detected.
IBM Watson OpenScale provides comprehensive monitoring for AI models, including fairness, quality, drift, and explainability. It allows users to set thresholds for key metrics and receive alerts when models deviate from expected behavior. OpenScale also supports what-if analysis and automated retraining workflows.
Prometheus and Grafana are widely used open-source tools for monitoring infrastructure and application metrics. They can be integrated with ML pipelines to track resource usage, latency, and other operational KPIs.
Effective monitoring platforms not only detect problems but also provide actionable insights and support automated remediation, such as retraining or rolling back models.
4.4 Automated Testing Frameworks
Automated testing is a cornerstone of reliable MLOps. Testing frameworks ensure that data pipelines, model code, and deployment scripts work as expected and that changes do not introduce regressions or errors.
Pytest is a popular Python testing framework that can be used to write unit, integration, and functional tests for ML code. It supports fixtures, parameterization, and plugins for advanced testing scenarios.
Great Expectations is an open-source tool for validating, documenting, and profiling data. It allows teams to define data quality checks and automatically validate data at every stage of the pipeline.
CI/CD tools like Jenkins, GitHub Actions, and GitLab CI can be configured to run automated tests on every code or data change, ensuring that only validated models and pipelines are promoted to production.
4.5 Infrastructure as Code (IaC) and Resource Management
Infrastructure as Code (IaC) tools enable teams to define, provision, and manage cloud and on-premises resources using code. This approach ensures consistency, repeatability, and scalability of ML infrastructure.
Terraform and Ansible are widely used IaC tools for automating the setup of servers, storage, networking, and other resources required for ML workloads. They support version control, modularization, and integration with cloud providers.
Kubernetes, in addition to orchestration, provides advanced resource management features such as auto-scaling, rolling updates, and GPU scheduling. Run:ai extends Kubernetes with intelligent GPU orchestration, dynamic resource allocation, and support for distributed training, optimizing infrastructure for AI at scale.
4.6 AutoML and No-Code/Low-Code Platforms
AutoML platforms automate many of the repetitive and complex tasks in the ML lifecycle, such as data preprocessing, feature engineering, model selection, and hyperparameter optimization.
IBM AutoAI is a no-code tool that automates the end-to-end process of building, training, and deploying machine learning models. It supports structured data, time series, and integrates with Watson Pipelines for full workflow automation.
Dataiku offers a visual interface for building and deploying ML pipelines, supporting both code-first and no-code users. It enables rapid prototyping, collaboration, and integration with enterprise data sources and cloud platforms.
AutoML tools lower the barrier to entry for machine learning, accelerate experimentation, and help organizations scale AI initiatives with limited resources.
Example: Registering and Deploying a Model with MLflow
Below is a Python example demonstrating how to log, register, and deploy a model using MLflow:
python
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load data
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=42)
# Train model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Log model with MLflow
with mlflow.start_run():
mlflow.sklearn.log_model(model, "rf_model")
mlflow.log_metric("accuracy", model.score(X_test, y_test))
# Register model (requires MLflow Tracking Server)
result = mlflow.register_model(
"runs:/<run_id>/rf_model", "RandomForestClassifierModel"
)
print("Model registered:", result.name)Replace <run_id> with the actual run ID from your MLflow experiment.
Best Practices for MLOps Automation
Implementing MLOps automation is not just about adopting the latest tools—it’s about building robust, scalable, and reliable processes that ensure machine learning models deliver value in production. Drawing from industry guides (including IBM, Dataiku, and Run:ai), as well as practical experience, here are the best practices for MLOps automation across the entire AI lifecycle.
5.1 Define Clear Business Objectives and Success Metrics
Before automating any part of the ML workflow, it is essential to define clear business objectives and measurable success criteria. This ensures that automation efforts are aligned with organizational goals and that model performance can be objectively evaluated. For example, if the goal is to reduce customer churn, define what level of accuracy or recall is required for the model to be considered successful.
5.2 Standardize and Modularize Pipelines
Standardizing data and model pipelines makes automation more manageable and repeatable. Modular pipelines—where each stage (data ingestion, preprocessing, training, validation, deployment) is a separate, well-defined component—allow teams to reuse, test, and update parts of the workflow independently. Tools like Apache Airflow, IBM Watson Pipelines, and Dataiku facilitate the creation of modular, reusable workflows.
5.3 Automate Testing and Validation
Automated testing is critical for ensuring the reliability of data pipelines and models. Implement unit tests for data preprocessing scripts, integration tests for end-to-end pipelines, and validation checks for model performance. Use frameworks like Pytest for code testing and Great Expectations for data validation. Automated tests should be integrated into CI/CD pipelines to catch issues early and prevent faulty models from reaching production.
5.4 Implement Robust Version Control
Version control is not just for code—it should also cover data, models, and configuration files. Use tools like Git for code, DVC or MLflow for data and model versioning, and maintain detailed metadata for each experiment. This practice ensures reproducibility, enables rollback to previous versions, and supports collaboration across teams.
5.5 Monitor Models Continuously in Production
Once models are deployed, continuous monitoring is essential to detect issues such as data drift, performance degradation, or bias. Platforms like IBM Watson OpenScale provide automated monitoring for fairness, quality, drift, and explainability. Set up alerts and automated retraining triggers to respond quickly to any deviations from expected behavior.
5.6 Ensure Security, Compliance, and Governance
Security and compliance are critical in enterprise MLOps. Implement access controls, audit trails, and encryption for sensitive data and models. Use governance tools like IBM AI Factsheets and OpenPages to document model lineage, track approvals, and ensure regulatory compliance. Automated governance workflows help organizations meet legal and ethical standards while maintaining transparency.
5.7 Foster Collaboration and Communication
Successful MLOps automation requires collaboration between data scientists, engineers, DevOps, and business stakeholders. Use shared dashboards, documentation, and communication tools to keep everyone aligned. Platforms like Dataiku and IBM Cloud Pak for Data offer collaborative interfaces that support teamwork across the ML lifecycle.
5.8 Start Small, Iterate, and Scale
Begin automation efforts with a small, well-defined use case. Iterate based on feedback and gradually expand automation to cover more complex workflows and additional models. This incremental approach reduces risk, builds organizational confidence, and ensures that automation delivers tangible value.
Example: Automated Model Validation with Pytest
Below is a simple example of how to use Pytest to automate model validation in Python. This test checks that a trained model achieves a minimum accuracy on a test set.
python
import pytest
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
@pytest.fixture
def data():
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=42
)
return X_train, X_test, y_train, y_test
def test_model_accuracy(data):
X_train, X_test, y_train, y_test = data
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
assert accuracy > 0.85, f"Model accuracy {accuracy:.2f} is below threshold"
# Created/Modified files during execution:
print("pytest_model_validation.py")Case Studies and Examples of MLOps Automation
To truly understand the value and impact of MLOps automation, it is essential to look at real-world case studies and practical examples. These illustrate how organizations across industries leverage automation to streamline their machine learning workflows, improve model performance, and ensure robust, scalable AI operations. Below, we explore several scenarios, drawing on best practices and tools from IBM, Dataiku, Run:ai, and other leading platforms.
6.1 Automating Image Recognition Workflows
In the field of image recognition, automation is crucial for handling large volumes of data and frequent model updates. For example, a retail company might use automated pipelines to process product images, train deep learning models, and deploy them to production for real-time product identification.
A typical automated workflow includes data ingestion from cloud storage, preprocessing (such as resizing and normalization), model training using frameworks like TensorFlow or PyTorch, and automated evaluation. Tools like IBM Watson Pipelines or Apache Airflow orchestrate these steps, ensuring that new data triggers retraining and redeployment automatically.
Here is a simplified Python example using TensorFlow and Airflow-like logic:
python
import tensorflow as tf
from tensorflow.keras import layers, models
import os
def load_and_preprocess_images(image_dir):
# Load and preprocess images from directory
# (Implementation depends on your data structure)
pass
def train_model(X_train, y_train):
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=5)
return model
# Example pipeline step
if __name__ == "__main__":
X_train, y_train = load_and_preprocess_images("images/train")
model = train_model(X_train, y_train)
model.save("image_model.h5")
# Created/Modified files during execution:
print("image_model.h5")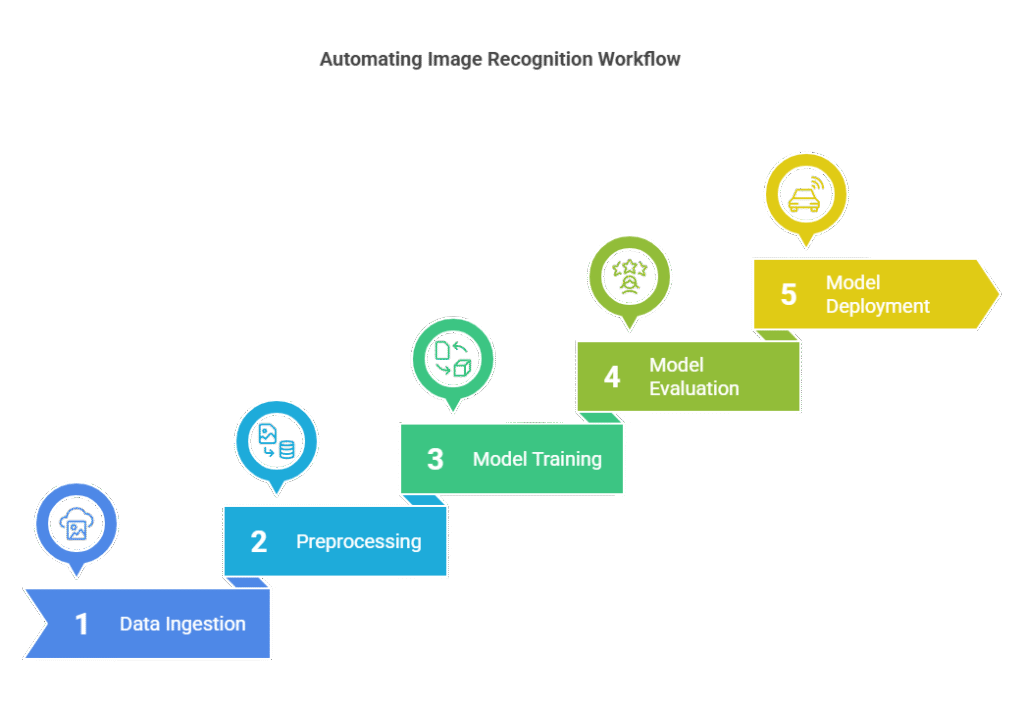
6.2 Automating Natural Language Processing (NLP) Pipelines
In NLP, automation enables organizations to process and analyze vast amounts of text data efficiently. For instance, a financial institution might automate sentiment analysis on customer feedback to improve service quality.
An automated NLP pipeline could include data extraction from databases, text cleaning, feature engineering (like tokenization and vectorization), model training, and deployment. IBM AutoAI or Dataiku can automate many of these steps, including model selection and hyperparameter tuning.
A Python example for automated sentiment analysis:
python
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
import joblib
# Sample data
texts = ["Great service!", "Very disappointed.", "Will buy again.", "Not satisfied."]
labels = [1, 0, 1, 0]
# Build pipeline
pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
pipeline.fit(texts, labels)
joblib.dump(pipeline, "sentiment_model.pkl")
# Created/Modified files during execution:
print("sentiment_model.pkl")6.3 Predictive Analytics in Business Operations
Predictive analytics is widely used in business to forecast sales, optimize inventory, or manage risk. Automation ensures that models are retrained as new data arrives, keeping predictions accurate and relevant.
For example, a logistics company might automate the entire workflow: data collection from IoT devices, feature engineering, model training, and deployment. Monitoring tools like IBM Watson OpenScale can track model performance, detect drift, and trigger retraining when necessary.
A simple Python example for automated retraining:
python
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
import joblib
# Load new data
data = pd.read_csv("new_sales_data.csv")
X = data.drop("sales", axis=1)
y = data["sales"]
# Train model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X, y)
joblib.dump(model, "sales_forecast_model.pkl")
# Created/Modified files during execution:
print("sales_forecast_model.pkl")6.4 End-to-End MLOps with IBM Watson Pipelines
IBM Watson Pipelines provides a visual and code-based interface for building, running, and monitoring end-to-end AI workflows. For example, a healthcare provider can automate the process of collecting patient data, training diagnostic models, and deploying them for real-time predictions.
The pipeline can be configured to trigger retraining when new data is available, run validation checks, and deploy updated models automatically. This reduces manual intervention, accelerates time-to-value, and ensures compliance with regulatory requirements.
6.5 Monitoring and Governance with IBM Watson OpenScale
After deployment, continuous monitoring is essential. IBM Watson OpenScale enables organizations to monitor deployed models for fairness, quality, drift, and explainability. For example, a bank can use OpenScale to ensure that credit scoring models remain unbiased and accurate over time.
If OpenScale detects a drop in model quality or a fairness issue, it can trigger automated retraining or rollback to a previous model version, ensuring responsible AI in production.
Challenges and Risks in MLOps Automation
As organizations scale their machine learning operations, they encounter a range of challenges and risks that can impact the reliability, security, and effectiveness of their AI initiatives. Understanding these challenges is essential for building robust, compliant, and sustainable MLOps pipelines. Drawing on insights from industry guides and practical experience, this article explores the most significant challenges and risks in MLOps automation and offers strategies to address them.
7.1 Data Quality and Data Drift
One of the most persistent challenges in MLOps is maintaining high data quality throughout the model lifecycle. Poor data quality can lead to inaccurate models, biased predictions, and ultimately, business failures. Data drift—when the statistical properties of input data change over time—can degrade model performance after deployment. Automated monitoring tools, such as IBM Watson OpenScale, can detect data drift and trigger retraining workflows, but organizations must also invest in robust data validation, cleaning, and governance processes to ensure ongoing data integrity.
7.2 Model Versioning and Reproducibility
As machine learning projects grow, managing multiple versions of models, datasets, and code becomes increasingly complex. Without proper versioning, it is difficult to reproduce results, audit decisions, or roll back to previous states in case of errors. Tools like MLflow, DVC, and Dataiku provide version control for models and data, but teams must establish clear policies and workflows for tracking changes, documenting experiments, and ensuring reproducibility across environments.
7.3 Security and Compliance
Security is a critical concern in MLOps, especially when handling sensitive data or deploying models in regulated industries. Risks include unauthorized access to data or models, data leakage, adversarial attacks, and compliance violations. Organizations must implement strong access controls, encryption, and audit trails, and use governance tools like IBM AI Factsheets and OpenPages to document model lineage and ensure regulatory compliance. Regular security assessments and automated compliance checks are essential to mitigate these risks.
7.4 Technical Debt and Infrastructure Complexity
Rapid experimentation and deployment can lead to technical debt—accumulated shortcuts or suboptimal solutions that hinder future development. Over time, this can result in fragile pipelines, inconsistent environments, and increased maintenance costs. Infrastructure complexity, especially in hybrid or multi-cloud environments, adds another layer of risk. Adopting Infrastructure as Code (IaC) practices, standardizing environments, and investing in automation tools like Kubernetes and Run:ai can help manage complexity and reduce technical debt.
7.5 Monitoring, Alerting, and Incident Response
Continuous monitoring of models in production is essential to detect performance degradation, bias, or operational failures. However, setting up effective monitoring and alerting systems can be challenging, especially when dealing with multiple models and data sources. Automated monitoring platforms like IBM Watson OpenScale provide dashboards and alerts for key metrics, but organizations must also define clear incident response procedures to address issues promptly and minimize business impact.
7.6 Collaboration and Communication Barriers
MLOps involves collaboration between data scientists, engineers, DevOps, business stakeholders, and compliance teams. Miscommunication or lack of shared understanding can lead to misaligned goals, duplicated efforts, or overlooked risks. Collaborative platforms like Dataiku and shared documentation practices can bridge these gaps, but fostering a culture of transparency and cross-functional teamwork is equally important.
7.7 Cost Management and Resource Optimization
Automating machine learning workflows can lead to increased resource consumption, especially when running large-scale experiments or retraining models frequently. Without proper resource management, organizations may face escalating cloud costs or underutilized infrastructure. Tools like Run:ai and Kubernetes enable dynamic resource allocation and cost optimization, but teams should also monitor usage, set budgets, and regularly review resource allocation strategies.
Example: Detecting Data Drift with Python
Below is a simple example of how to detect data drift using statistical tests in Python. This approach can be integrated into automated monitoring pipelines to trigger alerts or retraining when significant drift is detected.
python
import numpy as np
from scipy.stats import ks_2samp
# Simulated reference and new data distributions
reference_data = np.random.normal(loc=0, scale=1, size=1000)
new_data = np.random.normal(loc=0.5, scale=1, size=1000)
# Kolmogorov-Smirnov test for data drift
statistic, p_value = ks_2samp(reference_data, new_data)
print(f"KS statistic: {statistic:.3f}, p-value: {p_value:.3f}")
if p_value < 0.05:
print("Significant data drift detected. Consider retraining the model.")
else:
print("No significant data drift detected.")
# Created/Modified files during execution:
print("data_drift_detection.py")Conclusion and Next Steps in MLOps Automation
As organizations continue to scale their AI initiatives, MLOps automation has become a cornerstone for delivering reliable, efficient, and responsible machine learning solutions. Throughout this series, we have explored the strategies, tools, best practices, and real-world examples that define successful MLOps automation. In this final section, we summarize the key takeaways and outline actionable next steps for teams aiming to mature their MLOps capabilities.
8.1 Key Takeaways
MLOps automation is not just about technology—it is about building a culture and process that supports the entire machine learning lifecycle. The most important lessons include the need for clear business objectives, standardized and modular pipelines, robust version control, continuous monitoring, and strong governance. Tools like IBM Watson Pipelines, Dataiku, Run:ai, and open-source frameworks such as MLflow and Airflow provide the foundation for automating workflows, managing models, and ensuring compliance.
Automation enables teams to move faster, reduce manual errors, and focus on higher-value tasks such as model innovation and business impact. However, it also introduces new challenges, including data drift, technical debt, and the need for cross-functional collaboration. Addressing these challenges requires a combination of the right tools, best practices, and a commitment to continuous improvement.
8.2 Actionable Next Steps
To advance your organization’s MLOps automation journey, consider the following steps:
First, assess your current MLOps maturity by reviewing your workflows, toolchain, and team structure. Identify bottlenecks, manual processes, and areas where automation could deliver the most value.
Next, prioritize the implementation of modular, reusable pipelines using orchestration tools like Kubernetes or Watson Pipelines. Standardize data and model versioning practices with tools such as MLflow or DVC to ensure reproducibility and traceability.
Invest in automated testing and validation frameworks to catch issues early and maintain high-quality deployments. Integrate continuous monitoring and alerting platforms, such as IBM Watson OpenScale, to track model performance, fairness, and drift in production.
Strengthen governance by adopting solutions like AI Factsheets and OpenPages, which help document model lineage, manage approvals, and ensure regulatory compliance. Foster a culture of collaboration by encouraging communication between data scientists, engineers, and business stakeholders.
Finally, start small with pilot projects, iterate based on feedback, and gradually scale automation across more workflows and teams. Regularly review and update your processes to adapt to new challenges and opportunities.
8.3 Resources for Further Learning
To deepen your expertise in MLOps automation, explore the following resources:
IBM’s official documentation for Watson Pipelines, OpenScale, and AI Governance
Dataiku’s MLOps guides and product documentation
Run:ai’s platform tutorials for resource management and orchestration
Open-source projects such as MLflow, Apache Airflow, and DVC
Community forums, webinars, and case studies from leading AI practitioners
8.4 Example: Setting Up a Simple Automated ML Pipeline
Below is a Python example using MLflow and scikit-learn to demonstrate a basic automated pipeline for model training, evaluation, and registration:
python
import mlflow
import mlflow.sklearn
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# Load and split data
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=42)
# Start MLflow run
with mlflow.start_run():
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
mlflow.log_metric("accuracy", accuracy)
mlflow.sklearn.log_model(model, "rf_model")
print(f"Model accuracy: {accuracy:.2f}")
# Created/Modified files during execution:
print("MLflow run with model and metrics logged.")This example can be extended with additional steps for data validation, hyperparameter tuning, and deployment, forming the basis for a more comprehensive automated pipeline.
8.5 Final Thoughts
MLOps automation is a journey, not a destination. By embracing automation, organizations can unlock the full potential of AI, delivering models that are not only accurate and scalable but also transparent, fair, and trustworthy. The future of machine learning in the enterprise will be shaped by those who invest in robust, automated, and collaborative MLOps practices—ensuring that AI delivers real, sustainable business value.
References and Further Reading
A strong foundation in MLOps automation requires not only practical experience but also continuous learning from authoritative resources. This section provides a curated list of references and further reading materials, including books, official documentation, and online resources, to help you deepen your understanding and stay updated with the latest advancements in MLOps.
9.1 Books and Guides
For a comprehensive overview of MLOps concepts, strategies, and real-world applications, several books stand out. „Introducing MLOps: How to Scale Machine Learning in the Enterprise” by Mark Treveil and the Dataiku Team offers practical insights into scaling ML in business environments, covering topics such as risk management, governance, and automation. „Practical MLOps” provides hands-on guidance for building robust ML pipelines, managing data and model versioning, and addressing production challenges. The „Complete Guide to MLOps” by Run:ai is another valuable resource, focusing on workflow automation, resource management, and best practices for efficient machine learning operations.
9.2 Official Documentation
Staying current with the latest tools and platforms is essential for effective MLOps. Official documentation from leading vendors and open-source projects is a primary source of up-to-date information. IBM’s documentation for Watson Machine Learning, Watson OpenScale, Watson Pipelines, and AI Governance (including AI Factsheets and OpenPages) provides detailed guidance on automating, monitoring, and governing AI workflows. Dataiku’s product documentation and MLOps guides offer practical advice for implementing scalable, collaborative ML pipelines. For resource management and orchestration, Run:ai’s platform tutorials are highly recommended.
9.3 Online Courses and Tutorials
Numerous online courses and tutorials can help you build and refine your MLOps skills. Platforms like Coursera, edX, and Udacity offer specialized programs in MLOps, machine learning engineering, and AI deployment. Many of these courses include hands-on labs, real-world projects, and community support, making them ideal for both beginners and experienced practitioners.
9.4 Open-Source Projects and Community Resources
Engaging with open-source projects is a great way to learn from the community and contribute to the advancement of MLOps. Projects such as MLflow, Apache Airflow, DVC, and Kubeflow provide powerful tools for experiment tracking, workflow orchestration, data and model versioning, and scalable deployment. Community forums, GitHub repositories, and webinars from leading practitioners offer additional opportunities for learning and collaboration.
9.5 Example: Accessing Official Documentation in Python
Below is a simple Python example that demonstrates how to programmatically access and display documentation for a Python module, which is a useful habit for continuous learning:
import pydoc
# Display documentation for the 'os' module
print(pydoc.render_doc('os', "Help on %s"))
This approach can be extended to explore documentation for any installed package or module, helping you quickly find answers and deepen your understanding of the tools you use.
9.6 Staying Up to Date
The field of MLOps is evolving rapidly, with new tools, frameworks, and best practices emerging regularly. To stay informed, subscribe to newsletters, follow thought leaders on social media, and participate in conferences and meetups. Regularly reviewing the latest research papers and case studies will also help you anticipate trends and adopt innovative solutions in your own projects.

