
Introduction to Custom Deep Learning Architectures
The rapid evolution of deep learning has led to the development of a wide range of neural network architectures, many of which are available as ready-to-use models in popular frameworks. However, there are numerous scenarios where off-the-shelf solutions are insufficient, and designing a custom architecture becomes necessary. This introduction explores the motivations behind building custom deep learning models and provides an overview of the process from initial concept to production deployment.
1.1. Why Build Custom Architectures?
While pre-trained models and standard architectures like ResNet, BERT, or U-Net have revolutionized the field, they are not always optimal for every problem. Custom architectures are often required when the task is highly specialized, the data has unique characteristics, or there are specific constraints related to performance, interpretability, or deployment environment. For example, in medical imaging, a model may need to process multi-modal data or focus on extremely high-resolution images, which standard architectures may not handle efficiently. Similarly, in industrial applications, latency or memory constraints might necessitate a lightweight, tailor-made network. Building a custom architecture allows for the integration of domain knowledge, the design of novel layers or modules, and the fine-tuning of the model to achieve the best possible results for a given problem.
1.2. Overview of the Design-to-Production Pipeline
Designing and deploying a custom deep learning architecture is a multi-stage process that requires careful planning and execution. The journey typically begins with a thorough understanding of the problem and the data, followed by the conceptualization of a suitable model. The next steps involve designing the architecture, implementing and experimenting with different configurations, and rigorously validating the model’s performance. Once a satisfactory solution is found, attention shifts to preparing the model for production, which includes optimization, testing, and ensuring scalability. Finally, the deployment phase involves integrating the model into real-world systems, monitoring its performance, and establishing processes for maintenance and continuous improvement. Each stage of this pipeline presents its own challenges and opportunities, making the process of building custom deep learning architectures both complex and rewarding.
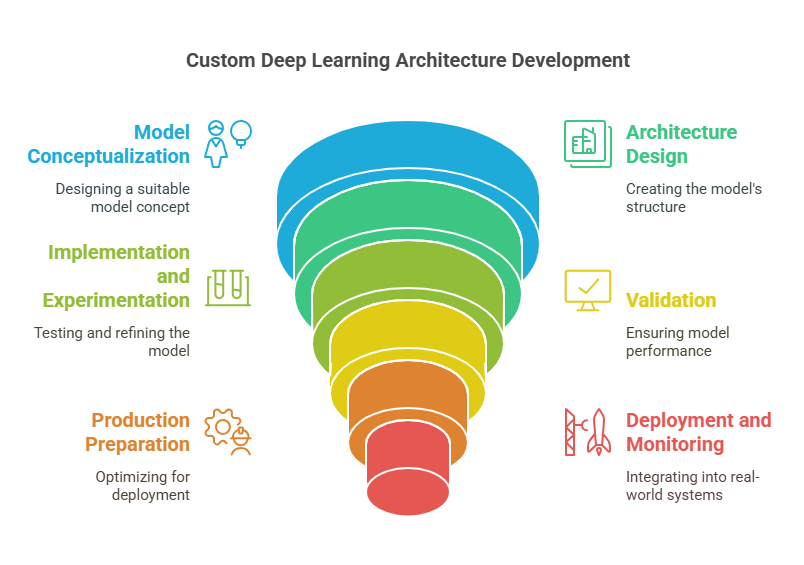
Conceptualizing a Deep Learning Solution
The foundation of any successful deep learning project lies in a well-thought-out concept. Before diving into model design or coding, it is essential to clearly define the problem, understand the data, and select the most promising approach. This stage sets the direction for the entire project and greatly influences the likelihood of achieving meaningful results.
2.1. Defining the Problem and Objectives
Every deep learning project should begin with a precise definition of the problem to be solved. This involves understanding the business or research context, identifying the specific task (such as classification, regression, segmentation, or generation), and setting measurable objectives. Clear objectives help determine what success looks like and guide decisions throughout the project. For example, in a medical diagnosis application, the goal might be to achieve a certain level of accuracy or sensitivity, while in an industrial setting, the focus could be on minimizing false positives or optimizing inference speed.
2.2. Data Collection and Preparation
Data is the cornerstone of deep learning. The quality, quantity, and relevance of the data directly impact the model’s performance. At this stage, it is important to gather diverse and representative datasets, ensuring they cover all relevant scenarios the model may encounter in production. Data preparation includes cleaning, labeling, handling missing values, and possibly augmenting the data to increase its diversity. In some cases, domain expertise is required to annotate data correctly or to engineer features that capture important patterns. Proper data preparation not only improves model accuracy but also helps prevent issues like overfitting or bias.
2.3. Selecting the Right Approach
Once the problem is defined and the data is prepared, the next step is to select the most suitable deep learning approach. This involves choosing the type of model architecture (such as convolutional neural networks for images, recurrent networks for sequences, or transformers for language tasks) and considering whether to use supervised, unsupervised, or reinforcement learning. The choice depends on the nature of the data, the complexity of the task, and the available computational resources. Sometimes, it is beneficial to start with a baseline model using a standard architecture and then iterate towards a custom solution as insights are gained from initial experiments.
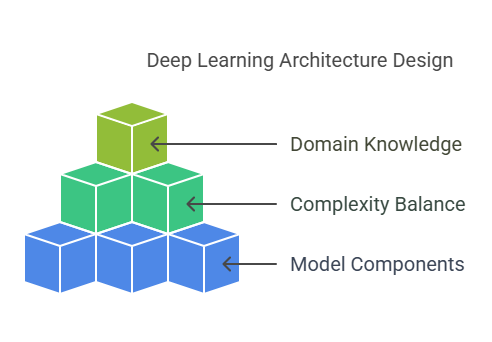
Designing the Architecture
Designing a custom deep learning architecture is a creative and technical process that bridges the gap between theoretical concepts and practical solutions. This stage involves making critical decisions about the structure of the neural network, the types of layers and operations to use, and how to incorporate domain-specific knowledge. The goal is to create a model that not only fits the data well but also meets the requirements of the task and deployment environment.
3.1. Choosing Model Components (Layers, Activations, etc.)
The first step in designing a neural network architecture is selecting the appropriate building blocks. These include the types of layers (such as convolutional, recurrent, or attention layers), activation functions (like ReLU, sigmoid, or softmax), and other components such as normalization layers, dropout, or residual connections. The choice of components depends on the nature of the data and the problem. For example, convolutional layers are well-suited for image data, while recurrent or transformer layers are more effective for sequential or language data. The arrangement and combination of these components determine the model’s capacity to learn complex patterns and generalize to new data.
3.2. Balancing Complexity and Performance
A key challenge in architecture design is finding the right balance between model complexity and performance. More complex models with many layers and parameters can capture intricate relationships in the data but are also more prone to overfitting and require greater computational resources. On the other hand, simpler models may not have enough capacity to solve challenging tasks. Techniques such as regularization, dropout, and early stopping can help prevent overfitting, while model pruning and parameter sharing can reduce complexity without sacrificing too much accuracy. It is often beneficial to start with a simple architecture and gradually increase complexity based on validation results and performance metrics.
3.3. Incorporating Domain Knowledge
Integrating domain knowledge into the architecture can significantly enhance model performance and interpretability. This might involve designing custom layers or modules that reflect known structures in the data, such as spatial hierarchies in images or temporal dependencies in time series. In some cases, domain knowledge can guide the choice of input features, the design of loss functions, or the selection of evaluation metrics. Collaborating with domain experts during the design phase ensures that the model is tailored to the specific characteristics and requirements of the application, leading to more robust and effective solutions.
Implementation and Experimentation
Once the architecture is designed, the next phase is to bring the concept to life through implementation and systematic experimentation. This stage is where ideas are translated into code, models are trained and evaluated, and insights are gained through iterative testing. Effective implementation and experimentation are crucial for refining the architecture, improving performance, and ensuring the model is robust and reliable.
4.1. Prototyping with Deep Learning Frameworks
Modern deep learning frameworks such as TensorFlow, PyTorch, and Keras have made it easier than ever to prototype custom architectures. These tools provide flexible APIs for defining layers, loss functions, and training loops, allowing developers to quickly implement and test new ideas. Prototyping typically starts with building a minimal version of the model to verify that the architecture works as intended. This phase often involves experimenting with different configurations, such as changing the number of layers, adjusting hyperparameters, or trying alternative activation functions. Rapid prototyping helps identify potential issues early and accelerates the development process.
4.2. Hyperparameter Tuning and Model Selection
Hyperparameters—such as learning rate, batch size, number of epochs, and regularization strength—play a significant role in the performance of deep learning models. Tuning these parameters is an iterative process that involves running multiple experiments, analyzing results, and selecting the best configuration. Techniques like grid search, random search, or more advanced methods such as Bayesian optimization can be used to systematically explore the hyperparameter space. Model selection is closely tied to this process, as it involves comparing different architectures and training runs to identify the model that achieves the best balance between accuracy, generalization, and efficiency.
4.3. Evaluation Metrics and Validation
Evaluating the model’s performance requires choosing appropriate metrics that reflect the objectives of the project. For classification tasks, metrics like accuracy, precision, recall, and F1-score are commonly used. For regression, mean squared error or mean absolute error may be more relevant. In some cases, domain-specific metrics are necessary to capture the true value of the model’s predictions. Validation is typically performed using a hold-out validation set or cross-validation to ensure that the model generalizes well to unseen data. Careful evaluation and validation help detect overfitting, underfitting, or data leakage, and provide confidence that the model will perform reliably in production.
Preparing for Production
Transitioning a deep learning model from the experimental phase to a production environment is a critical step that requires careful preparation. This stage ensures that the model is not only accurate but also efficient, scalable, and robust enough to handle real-world data and operational challenges. Proper preparation for production deployment can make the difference between a successful AI solution and one that fails to deliver value in practice.
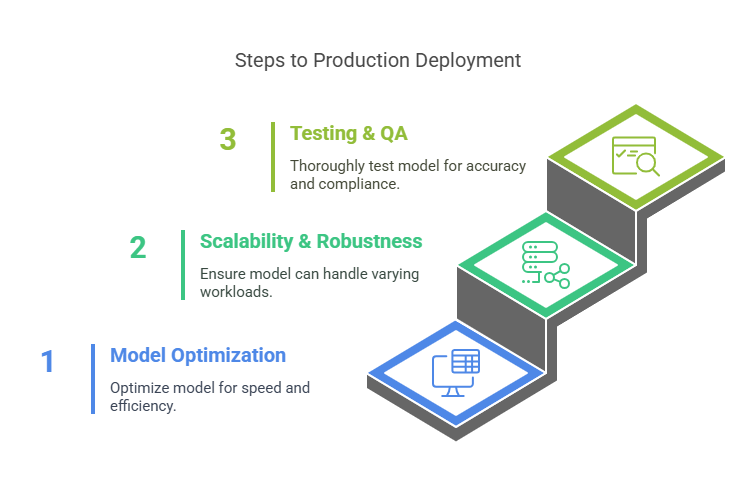
5.1. Model Optimization and Compression
Before deployment, it is essential to optimize the model for speed, memory usage, and resource efficiency. Techniques such as pruning, quantization, and knowledge distillation can significantly reduce the size and computational requirements of the model without sacrificing much accuracy. Model compression is particularly important for applications running on edge devices, mobile phones, or embedded systems, where hardware resources are limited. Additionally, converting the model to a format compatible with the target platform (such as TensorFlow Lite, ONNX, or Core ML) ensures smooth integration and efficient inference.
5.2. Ensuring Scalability and Robustness
A production-ready model must be able to handle varying workloads and unexpected scenarios. Scalability involves designing the system so that it can process large volumes of data or serve many users simultaneously, often by leveraging cloud infrastructure or distributed computing. Robustness means the model can maintain reliable performance even when faced with noisy, incomplete, or adversarial data. Techniques such as input validation, anomaly detection, and fallback mechanisms help safeguard the system against failures and ensure consistent results. Stress testing and monitoring under realistic conditions are also crucial to identify and address potential bottlenecks or vulnerabilities before deployment.
5.3. Testing and Quality Assurance
Thorough testing is vital to ensure that the model performs as expected in production. This includes not only evaluating accuracy and efficiency but also checking for edge cases, integration issues, and compliance with relevant standards or regulations. Automated testing pipelines can be set up to validate the model’s behavior with new data, monitor for performance drift, and trigger alerts if anomalies are detected. Quality assurance processes should also involve collaboration with domain experts to verify that the model’s predictions are meaningful and actionable in the real-world context. Documentation and reproducibility are important as well, making it easier to maintain, update, or retrain the model as requirements evolve.
Deployment and Monitoring
Deploying a deep learning model is not the end of the journey—it marks the beginning of its real-world operation. This phase involves integrating the model into production systems, ensuring it runs efficiently, and continuously monitoring its performance to maintain reliability and relevance over time.
6.1. Model Deployment Strategies
There are several strategies for deploying deep learning models, depending on the application’s requirements and infrastructure. Common approaches include deploying as a REST API using frameworks like Flask or FastAPI, embedding the model directly into mobile or edge devices, or serving it through cloud-based platforms such as AWS SageMaker or Google AI Platform. The choice of deployment method affects scalability, latency, and maintenance. For example, deploying as a web service allows for easy updates and scaling, while edge deployment minimizes latency and can operate offline.
Example: Deploying a model as a REST API with FastAPI
python
from fastapi import FastAPI
from pydantic import BaseModel
import torch
import torchvision.transforms as transforms
from PIL import Image
import io
app = FastAPI()
# Dummy model for illustration
class DummyModel(torch.nn.Module):
def forward(self, x):
return torch.tensor([[0.1, 0.9]])
model = DummyModel()
transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])
class ImageInput(BaseModel):
image_bytes: bytes
@app.post("/predict")
def predict(input: ImageInput):
image = Image.open(io.BytesIO(input.image_bytes))
tensor = transform(image).unsqueeze(0)
with torch.no_grad():
output = model(tensor)
prediction = output.argmax(dim=1).item()
return {"prediction": prediction}This example shows how to wrap a PyTorch model in a FastAPI service, allowing clients to send images and receive predictions.
6.2. Monitoring Model Performance
Once deployed, it is crucial to monitor the model’s performance in production. This involves tracking metrics such as accuracy, latency, throughput, and resource usage. Monitoring helps detect issues like model drift, where the model’s performance degrades over time due to changes in the data distribution. Automated monitoring systems can trigger alerts if performance drops below a certain threshold, enabling rapid response and retraining if necessary.
Example: Simple monitoring of prediction accuracy
python
# Pseudocode for monitoring accuracy
correct = 0
total = 0
def log_prediction(y_true, y_pred):
global correct, total
if y_true == y_pred:
correct += 1
total += 1
if total % 100 == 0:
print(f"Current accuracy: {correct / total:.2%}")This snippet demonstrates a basic way to log and monitor accuracy over time.
6.3. Handling Model Updates and Retraining
Models in production often need to be updated or retrained as new data becomes available or as requirements change. A robust deployment pipeline should support versioning, rollback, and automated retraining. Continuous integration and deployment (CI/CD) practices can help automate these processes, ensuring that updates are tested and deployed safely.
Example: Automated retraining pipeline (conceptual)
python
def retrain_model(new_data):
# Load new data
# Preprocess data
# Train model
# Evaluate model
# Save and deploy new model version
pass
# Trigger retraining based on monitoring results or schedule
if performance_drops or scheduled_time:
retrain_model(latest_data)This conceptual code outlines how retraining can be triggered automatically based on monitoring or a schedule.
Best Practices and Lessons Learned
The journey from designing to deploying custom deep learning architectures is filled with both technical and organizational challenges. Over time, practitioners have developed a set of best practices and key lessons that help ensure projects are successful, maintainable, and impactful. Embracing these principles can save time, reduce errors, and lead to more robust AI solutions.
7.1. Documentation and Reproducibility
Comprehensive documentation is essential at every stage of a deep learning project. This includes clear explanations of the model architecture, data preprocessing steps, training procedures, and evaluation metrics. Well-documented code and configuration files make it easier for others (and your future self) to understand, maintain, and extend the project. Reproducibility is equally important: using version control for code and data, fixing random seeds, and recording environment details ensure that experiments can be reliably repeated. Tools like Jupyter notebooks, experiment tracking platforms (such as MLflow or Weights & Biases), and containerization (using Docker) further support reproducibility and collaboration.
7.2. Collaboration and Communication
Deep learning projects often require close collaboration between data scientists, engineers, domain experts, and stakeholders. Effective communication helps align expectations, clarify requirements, and surface potential issues early. Regular meetings, shared documentation, and collaborative tools (like shared repositories and project management boards) foster transparency and teamwork. Involving domain experts throughout the process ensures that the model addresses real-world needs and that its outputs are interpretable and actionable.
7.3. Continuous Learning and Improvement
The field of deep learning evolves rapidly, with new techniques, architectures, and tools emerging all the time. Staying up to date through research papers, conferences, and community forums is crucial for maintaining a competitive edge. Continuous learning also means being open to feedback and iterating on models based on real-world performance and user input. Establishing a culture of experimentation—where failures are seen as learning opportunities—encourages innovation and leads to better long-term outcomes.
Case Studies and Real-World Applications
Examining real-world case studies provides valuable insights into how custom deep learning architectures are designed, implemented, and deployed to solve practical problems. These examples highlight the challenges faced, the solutions developed, and the impact achieved, offering inspiration and guidance for future projects.
8.1. Industry Examples
Custom deep learning models have transformed numerous industries. In healthcare, for instance, convolutional neural networks (CNNs) are used for medical image analysis, enabling early detection of diseases such as cancer from X-rays or MRIs. In finance, recurrent neural networks (RNNs) and transformer-based models help with fraud detection and algorithmic trading by analyzing large volumes of transactional data in real time. The automotive industry leverages deep learning for autonomous driving, where models process sensor data to recognize objects, predict movements, and make driving decisions. Each of these applications required tailored architectures and careful tuning to meet strict accuracy, latency, and safety requirements.
8.2. Lessons from Deployment
Deploying deep learning models in real-world settings often reveals challenges that are not apparent during development. For example, a model trained on high-quality, curated data may encounter noisy or incomplete data in production, leading to performance drops. In one case, a retail company deploying a recommendation system found that user behavior changed seasonally, requiring regular retraining and monitoring to maintain relevance. Another example comes from the energy sector, where predictive maintenance models for equipment had to be robust against rare but critical failure events, prompting the use of anomaly detection and ensemble methods. These experiences underscore the importance of continuous monitoring, data quality management, and the ability to adapt models as conditions evolve.
8.3. Impact and Measurable Outcomes
The ultimate goal of deploying custom deep learning architectures is to deliver measurable value. In e-commerce, personalized recommendation engines have led to significant increases in sales and customer engagement. In logistics, route optimization models have reduced delivery times and operational costs. In environmental monitoring, deep learning models analyzing satellite imagery have improved disaster response and resource management. These successes are typically measured through key performance indicators (KPIs) such as accuracy, precision, recall, cost savings, or user satisfaction. Demonstrating clear, quantifiable outcomes not only justifies the investment in AI but also builds trust and support for future initiatives.
Next-Generation Programming: Working Side by Side with AI Agents
The Programmer and the AI Agent: Human-Machine Collaboration in Modern Projects
Advanced Deep Learning Techniques: From Transformers to Generative Models

