
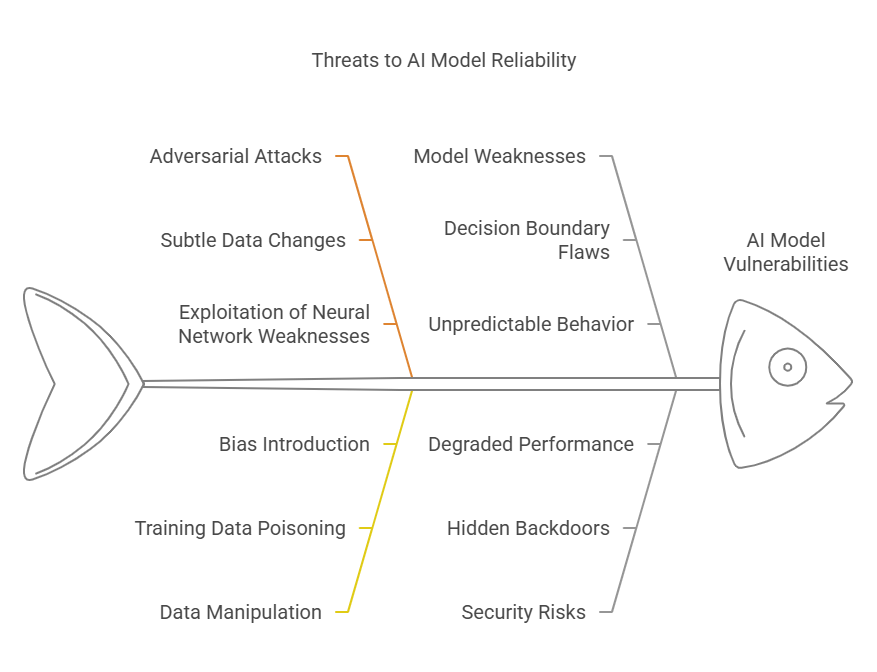
Introduction: What Are Adversarial Attacks and Data Manipulation in AI?
Artificial intelligence models, especially those based on deep learning, have achieved remarkable success in fields such as image recognition, natural language processing, and autonomous systems. However, as these models become more widely adopted, their vulnerabilities are also becoming more apparent. Two of the most significant threats to AI systems are adversarial attacks and data manipulation.
Adversarial attacks are deliberate attempts to fool AI models by introducing subtle, often imperceptible, changes to input data. For example, an attacker might add carefully crafted noise to an image so that a model misclassifies it, even though the changes are invisible to the human eye. These attacks exploit the way neural networks process information, revealing weaknesses in their decision boundaries.
Data manipulation, on the other hand, involves tampering with the data used to train or evaluate AI models. This can include poisoning the training dataset with malicious samples, introducing bias, or altering labels. Such manipulations can degrade model performance, introduce hidden backdoors, or cause the model to behave unpredictably in production.
Both adversarial attacks and data manipulation pose serious risks to the reliability, security, and trustworthiness of AI systems. Understanding these threats is the first step toward building more robust and resilient models.
Types of Adversarial Attacks on AI Models
Adversarial attacks can be categorized based on the attacker’s knowledge, goals, and the techniques used. Here are some of the most common types:
White-box Attacks
In white-box attacks, the attacker has full access to the model’s architecture, parameters, and training data. This allows them to craft highly effective adversarial examples by exploiting specific weaknesses in the model. Techniques such as the Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD) are popular in this category.
Black-box Attacks
Black-box attacks assume the attacker has no knowledge of the model’s internal workings. Instead, they can only observe the model’s outputs for given inputs. Attackers may use techniques like transferability (where adversarial examples generated for one model also fool another) or query-based methods to generate effective attacks.
Targeted vs. Untargeted Attacks
In targeted attacks, the adversary aims to mislead the model into making a specific incorrect prediction (for example, classifying a stop sign as a speed limit sign). In untargeted attacks, the goal is simply to cause any incorrect prediction, regardless of the output class.
Evasion Attacks
Evasion attacks occur at inference time, where adversarial examples are crafted to bypass the model’s defenses and cause misclassification. These are the most widely studied and demonstrated attacks in the literature.
Poisoning Attacks
Poisoning attacks target the training phase by injecting malicious data into the training set. This can degrade the model’s accuracy or introduce specific vulnerabilities that can be exploited later.
Physical Attacks
Some adversarial attacks are designed to work in the physical world, not just in digital simulations. For example, attackers might place stickers on road signs to fool autonomous vehicle perception systems, or wear specially designed glasses to evade facial recognition.
Examples of Data Manipulation in Practice
Data manipulation is a critical aspect of working with AI models, particularly when dealing with adversarial attacks. Here are some practical examples using Python code that demonstrate common data manipulation techniques:
python
import numpy as np
from PIL import Image
import torch
import torchvision.transforms as transforms
def create_adversarial_example(image, epsilon=0.01):
"""
Creates a basic adversarial example by adding small perturbations
to the original image data.
Args:
image: Input image as numpy array
epsilon: Perturbation size
Returns:
Manipulated image data
"""
# Convert image to float32
image = image.astype(np.float32)
# Create random noise
noise = np.random.normal(0, 1, image.shape)
# Add scaled noise to image
perturbed_image = image + epsilon * noise
# Clip values to valid range [0, 1]
perturbed_image = np.clip(perturbed_image, 0, 1)
return perturbed_image
def poison_training_data(X_train, y_train, poison_ratio=0.1):
"""
Poisons a portion of training data by flipping labels.
Args:
X_train: Training features
y_train: Training labels
poison_ratio: Ratio of data to poison
Returns:
Poisoned training data and labels
"""
num_samples = len(y_train)
num_poison = int(num_samples * poison_ratio)
# Randomly select indices to poison
poison_idx = np.random.choice(num_samples, num_poison, replace=False)
# Create copies to avoid modifying original data
X_poisoned = X_train.copy()
y_poisoned = y_train.copy()
# Flip labels for selected samples
y_poisoned[poison_idx] = 1 - y_poisoned[poison_idx]
return X_poisoned, y_poisoned
# Example usage
if __name__ == "__main__":
# Create sample data
sample_image = np.random.rand(28, 28) # Random 28x28 image
X_train = np.random.rand(1000, 28, 28) # 1000 random images
y_train = np.random.randint(0, 2, 1000) # Binary labels
# Create adversarial example
perturbed_image = create_adversarial_example(sample_image)
print("Original image shape:", sample_image.shape)
print("Perturbed image shape:", perturbed_image.shape)
# Poison training data
X_poisoned, y_poisoned = poison_training_data(X_train, y_train)
print("\nOriginal labels sum:", y_train.sum())
print("Poisoned labels sum:", y_poisoned.sum())Mechanisms for Detecting and Monitoring Adversarial Attacks
Implementing robust detection mechanisms is crucial for protecting AI models against adversarial attacks. Here’s a Python implementation of common detection techniques:
python
import numpy as np
from sklearn.metrics import accuracy_score
from sklearn.ensemble import IsolationForest
class AdversarialDetector:
def __init__(self, threshold=0.95):
"""
Initialize detector with confidence threshold.
Args:
threshold: Confidence threshold for detection
"""
self.threshold = threshold
self.anomaly_detector = IsolationForest(contamination=0.1)
def detect_input_manipulation(self, original_input, current_input):
"""
Detects if input has been manipulated beyond acceptable threshold.
Args:
original_input: Original input data
current_input: Potentially manipulated input
Returns:
Boolean indicating if manipulation detected
"""
difference = np.abs(original_input - current_input)
max_difference = np.max(difference)
return max_difference > self.threshold
def monitor_model_behavior(self, model, X_test, y_test, window_size=100):
"""
Monitors model behavior for suspicious patterns.
Args:
model: ML model to monitor
X_test: Test features
y_test: Test labels
window_size: Size of monitoring window
Returns:
Dictionary with monitoring metrics
"""
predictions = model.predict(X_test)
accuracies = []
# Calculate accuracy in sliding windows
for i in range(0, len(y_test) - window_size + 1):
window_acc = accuracy_score(
y_test[i:i+window_size],
predictions[i:i+window_size]
)
accuracies.append(window_acc)
return {
'mean_accuracy': np.mean(accuracies),
'std_accuracy': np.std(accuracies),
'min_accuracy': np.min(accuracies),
'max_accuracy': np.max(accuracies)
}
def detect_anomalies(self, X_train, X_test):
"""
Detects anomalous inputs using isolation forest.
Args:
X_train: Training data
X_test: Test data to check for anomalies
Returns:
Array of boolean indicators for anomalies
"""
# Fit detector on training data
self.anomaly_detector.fit(X_train)
# Predict anomalies (-1 for anomalies, 1 for normal)
predictions = self.anomaly_detector.predict(X_test)
# Convert to boolean array (True for anomalies)
return predictions == -1
# Example usage
if __name__ == "__main__":
# Create sample data
X_train = np.random.rand(1000, 10)
X_test = np.random.rand(100, 10)
y_test = np.random.randint(0, 2, 100)
# Initialize detector
detector = AdversarialDetector(threshold=0.1)
# Test input manipulation detection
original = np.random.rand(10)
manipulated = original + np.random.normal(0, 0.2, 10)
is_manipulated = detector.detect_input_manipulation(original, manipulated)
print("Input manipulation detected:", is_manipulated)
# Test anomaly detection
anomalies = detector.detect_anomalies(X_train, X_test)
print("\nNumber of anomalies detected:", sum(anomalies))
# Create dummy model for monitoring
class DummyModel:
def predict(self, X):
return np.random.randint(0, 2, len(X))
# Test model monitoring
model = DummyModel()
metrics = detector.monitor_model_behavior(model, X_test, y_test)
print("\nMonitoring metrics:", metrics)This code provides a comprehensive framework for detecting and monitoring adversarial attacks, including:
Input manipulation detection
Model behavior monitoring
Anomaly detection using isolation forests
Sliding window accuracy analysis
Detecting and Monitoring Adversarial Attacks on AI Models
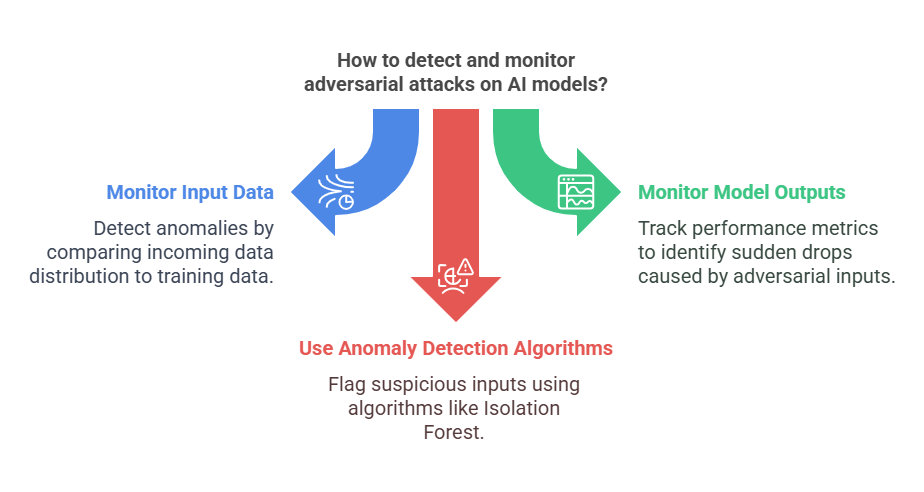
As AI models become more widely deployed in real-world applications, the need for robust detection and monitoring of adversarial attacks is critical. Adversarial attacks can degrade model performance, cause misclassifications, or even introduce security vulnerabilities. Therefore, organizations must implement effective mechanisms to detect, monitor, and respond to such threats.
One of the most common approaches is to monitor the input data for unusual patterns or anomalies. For example, input drift detection compares the distribution of incoming data to the data used during model training or evaluation. If a significant deviation is detected, it may indicate a potential adversarial attack or data manipulation. Tools like IBM Watson OpenScale and Dataiku provide built-in features for input drift detection, allowing teams to set statistical thresholds and receive alerts when anomalies occur.
Another important aspect is monitoring model outputs and performance metrics over time. By tracking metrics such as accuracy, precision, recall, and loss, teams can identify sudden drops in performance that may be caused by adversarial inputs. Automated validation feedback loops, as described in Dataiku’s MLOps features, enable continuous evaluation of model predictions against new validation datasets. This helps in early detection of attacks and supports automated retraining or redeployment if necessary.
Additionally, anomaly detection algorithms, such as Isolation Forest or One-Class SVM, can be used to flag suspicious inputs. These algorithms learn the normal behavior of the data and can identify outliers that may represent adversarial examples. Integrating these techniques into the MLOps pipeline ensures that models are continuously protected and that any attack is quickly identified and addressed.
Testing Model Robustness: Methods and Tools
Testing the robustness of AI models against adversarial attacks and data manipulation is a crucial step in ensuring their reliability and security. Robustness testing involves evaluating how well a model can withstand intentional or unintentional perturbations in the input data.
One widely used method is adversarial testing, where synthetic adversarial examples are generated and fed to the model to observe its behavior. Libraries such as Foolbox, CleverHans, and Adversarial Robustness Toolbox (ART) provide tools for generating adversarial samples using techniques like Fast Gradient Sign Method (FGSM), Projected Gradient Descent (PGD), and more. By systematically testing the model with these examples, developers can identify vulnerabilities and improve model defenses.
Another approach is to perform stress testing by introducing noise, missing values, or corrupted data into the input pipeline. This helps evaluate the model’s ability to handle real-world data imperfections and resist manipulation. Automated pipelines can be set up to regularly test models with various types of data perturbations as part of the CI/CD process in MLOps.
Below is a Python example using the Adversarial Robustness Toolbox (ART) to test a simple classifier’s robustness against FGSM attacks:
python
import numpy as np
from art.attacks.evasion import FastGradientMethod
from art.estimators.classification import SklearnClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load data and train a simple model
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Wrap the model with ART's classifier
classifier = SklearnClassifier(model=model)
# Generate adversarial examples using FGSM
attack = FastGradientMethod(estimator=classifier, eps=0.2)
X_test_adv = attack.generate(x=X_test)
# Evaluate model accuracy on clean and adversarial data
clean_accuracy = np.sum(model.predict(X_test) == y_test) / len(y_test)
adv_accuracy = np.sum(model.predict(X_test_adv) == y_test) / len(y_test)
print(f"Accuracy on clean test data: {clean_accuracy:.2f}")
print(f"Accuracy on adversarial test data: {adv_accuracy:.2f}")This code demonstrates how to use ART to generate adversarial examples and measure the impact on model accuracy. A significant drop in accuracy on adversarial data indicates that the model is vulnerable and may require additional defenses, such as adversarial training or input preprocessing.
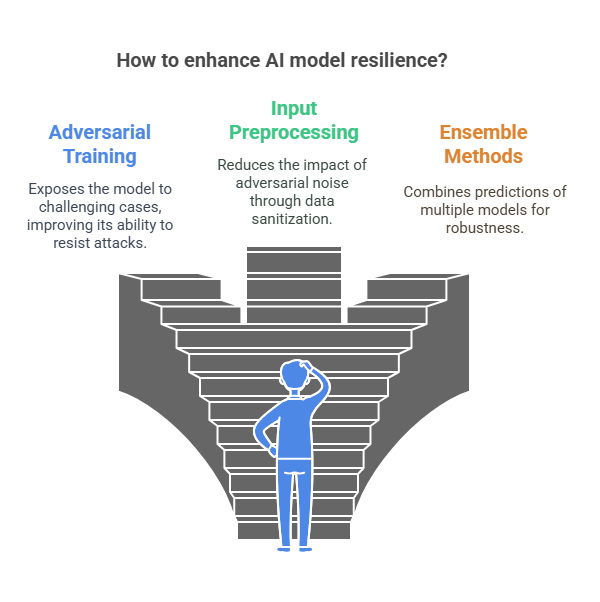
Practical Strategies for Strengthening AI Model Resilience
Building AI models that are resilient to adversarial attacks and data manipulation is a complex but essential task for any organization deploying machine learning in production. There are several practical strategies that can be implemented to enhance the robustness of AI systems.
One of the most effective approaches is adversarial training. This technique involves augmenting the training dataset with adversarial examples—inputs that have been intentionally perturbed to mislead the model. By exposing the model to these challenging cases during training, it learns to recognize and resist similar attacks in the future. Adversarial training can be implemented using libraries such as Adversarial Robustness Toolbox (ART) or CleverHans, which provide utilities for generating adversarial samples and integrating them into the training loop.
Another important strategy is input preprocessing and data sanitization. Techniques such as feature scaling, normalization, and outlier removal can help reduce the impact of adversarial noise. Additionally, using robust feature extraction methods—such as those based on statistical properties or domain knowledge—can make it harder for attackers to craft effective adversarial examples.
Ensemble methods also play a significant role in improving model resilience. By combining the predictions of multiple models, ensembles can reduce the likelihood that a single adversarial example will fool the entire system. Techniques like bagging, boosting, or stacking can be used to create diverse model ensembles that are more robust to attacks.
Regular monitoring and validation of model performance are crucial. Implementing feedback loops that continuously evaluate the model on new data, including adversarial and manipulated samples, helps detect vulnerabilities early. Automated retraining and redeployment pipelines, as supported by modern MLOps platforms like Dataiku or IBM Watson OpenScale, ensure that models remain robust as new threats emerge.
Finally, explainability tools such as SHAP and LIME can be used to analyze model decisions and identify suspicious patterns that may indicate adversarial manipulation. By understanding which features influence predictions, data scientists can spot anomalies and take corrective action.
Challenges and Limitations in Protecting AI Models
Despite the availability of advanced defense mechanisms, protecting AI models from adversarial attacks and data manipulation remains a significant challenge. One of the main difficulties is the evolving nature of attack techniques. As defenses improve, attackers develop new methods to bypass them, leading to a constant arms race between adversaries and defenders.
Adversarial training, while effective, can be computationally expensive and may not generalize well to all types of attacks. It also requires access to representative adversarial examples, which may not always be available. Overfitting to specific attack patterns during adversarial training can leave models vulnerable to novel or unseen attacks.
Input preprocessing and data sanitization techniques can help, but they are not foolproof. Sophisticated attackers can design perturbations that survive common preprocessing steps or exploit weaknesses in feature extraction. Moreover, aggressive data cleaning may inadvertently remove valuable information, reducing model accuracy on legitimate inputs.
Ensemble methods increase robustness but also add complexity and computational overhead. Maintaining and updating multiple models can be resource-intensive, and ensembles are not immune to coordinated attacks that target all models simultaneously.
Another major challenge is the lack of standardized benchmarks and evaluation metrics for model robustness. While tools and libraries exist for generating adversarial examples and testing defenses, there is no universal agreement on how to measure and compare resilience across different models and attack scenarios.
Finally, explainability tools, while useful for detecting anomalies, are not always able to pinpoint the root cause of adversarial behavior. Interpretability methods can be computationally intensive and may not scale well to large or complex models.
The Future of AI Model Security
The landscape of AI model security is rapidly evolving as adversarial attacks and data manipulation techniques become more sophisticated. In the coming years, we can expect several key trends and innovations to shape the future of AI model resilience.
First, the integration of AI governance and compliance frameworks will become standard practice. As highlighted in recent MLOps guides and platforms like IBM Watson OpenScale, organizations are increasingly required to document, monitor, and audit their AI models throughout the entire lifecycle. This includes tracking model metadata, performance metrics, fairness, and drift, all of which are essential for regulatory compliance and transparency. Automated tools for AI governance will help ensure that models remain secure, explainable, and trustworthy, even as they are updated or retrained.
Second, the adoption of advanced monitoring and feedback loops will continue to grow. Modern platforms such as Dataiku and IBM Cloud Pak for Data already offer features like input drift detection, automated validation feedback, and retraining pipelines. These capabilities allow organizations to detect anomalies, respond to attacks in real time, and maintain high model performance. The future will likely see even more seamless integration of these monitoring tools with automated defense mechanisms, enabling AI systems to self-heal and adapt to new threats.
Another important trend is the development of robust benchmarking and testing standards for AI security. As the field matures, we can expect the emergence of industry-wide benchmarks for evaluating model robustness against adversarial attacks and data manipulation. This will make it easier for organizations to compare solutions, identify best practices, and ensure that their models meet the highest security standards.
Finally, the rise of foundation models and large language models (LLMs) introduces new challenges and opportunities for AI security. These models are powerful but also more susceptible to subtle attacks and data poisoning due to their scale and complexity. The future of AI security will involve specialized tools and frameworks for monitoring, defending, and governing these advanced models, ensuring that they can be safely deployed in critical applications.
In summary, the future of AI model security will be defined by greater automation, transparency, and standardization. Organizations that invest in robust governance, continuous monitoring, and proactive defense strategies will be best positioned to navigate the evolving threat landscape.
Summary and Further Resources
AI model resilience to adversarial attacks and data manipulation is a critical concern for any organization deploying machine learning in production. As discussed, adversarial attacks can exploit model vulnerabilities, while data manipulation can undermine the integrity of training and evaluation processes. To address these challenges, practitioners must adopt a multi-layered approach that includes adversarial training, input preprocessing, ensemble methods, and continuous monitoring.
The future of AI security will be shaped by the integration of governance frameworks, advanced monitoring tools, and standardized benchmarks. Platforms like IBM Watson OpenScale and Dataiku are already leading the way by providing automated solutions for model monitoring, validation, and compliance. As foundation models and LLMs become more prevalent, specialized security tools will be essential to protect these complex systems.
For those interested in deepening their knowledge, here are some recommended resources:
Adversarial Robustness Toolbox (ART): An open-source library for adversarial machine learning in Python.
IBM Watson OpenScale: A platform for monitoring, explaining, and governing AI models.
Dataiku MLOps: Enterprise-scale tools for model monitoring, retraining, and governance.
CleverHans: A Python library for benchmarking machine learning systems’ vulnerability to adversarial examples.
Papers With Code: Adversarial Attacks: A collection of research papers and code implementations on adversarial machine learning.
Security and Resilience of AI Agents: Detection, Defense, and Self-Healing After Adversarial Attacks

