
Introduction to AI Agent Security
As artificial intelligence (AI) agents become increasingly integrated into critical systems and everyday applications, ensuring their security is paramount. AI agents—autonomous or semi-autonomous software entities capable of perceiving their environment, making decisions, and acting upon them—are vulnerable to a range of security threats that can compromise their functionality, reliability, and trustworthiness.
AI agent security focuses on protecting these systems from malicious manipulation, unauthorized access, and adversarial attacks that aim to deceive or disrupt their decision-making processes. Unlike traditional software, AI agents often learn from data and adapt their behavior over time, which introduces unique challenges. Attackers can exploit these learning mechanisms by feeding manipulated data or crafting inputs designed to mislead the agent, potentially causing harmful or unintended outcomes.
The importance of securing AI agents extends beyond technical concerns. In domains such as healthcare, finance, autonomous vehicles, and critical infrastructure, compromised AI agents can lead to severe consequences, including financial loss, safety hazards, and erosion of public trust.
This article series will explore the various dimensions of AI agent security, starting with an understanding of the types of threats these agents face, followed by detection and defense strategies, and concluding with best practices and future research directions. By addressing these challenges, developers and organizations can build AI agents that are not only intelligent but also resilient and trustworthy.
Understanding Manipulation Threats
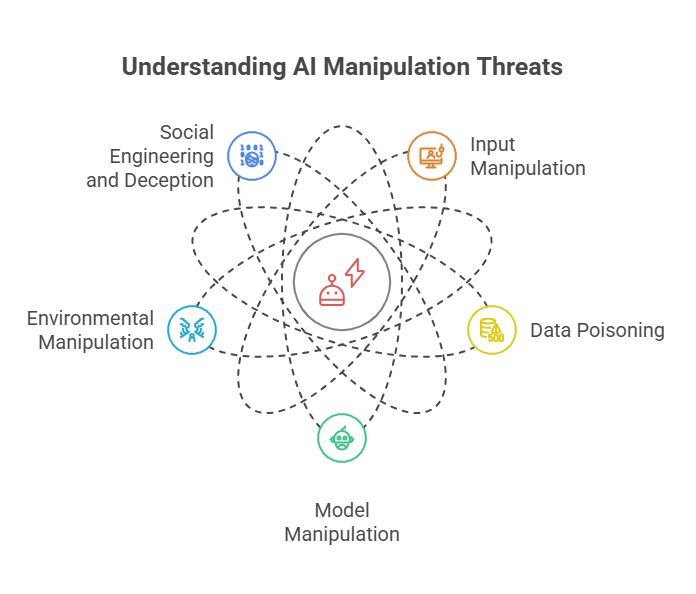
Manipulation threats pose a significant risk to AI agents by deliberately influencing their behavior to achieve malicious goals. Unlike random errors or system faults, manipulation attacks are intentional efforts by adversaries to exploit vulnerabilities in AI agents, often by altering inputs, environments, or internal states to mislead or control the agent’s decisions.
There are several common types of manipulation threats targeting AI agents:
Input Manipulation:
Attackers craft specific inputs designed to deceive the AI agent. This can include subtle changes to data that cause the agent to misclassify or make incorrect decisions. For example, in image recognition, slight pixel modifications can cause an AI to misidentify objects.
Data Poisoning:
During the training phase, adversaries inject corrupted or misleading data into the training set. This compromises the learning process, causing the AI agent to develop flawed models that behave incorrectly when deployed.
Model Manipulation:
Attackers may attempt to alter the AI agent’s internal model or parameters directly, either by exploiting software vulnerabilities or through insider threats. This can lead to biased or harmful agent behavior.
Environmental Manipulation:
In real-world settings, adversaries can manipulate the environment in which the AI agent operates. For instance, changing physical surroundings or sensor inputs to confuse autonomous vehicles or robots.
Social Engineering and Deception:
Manipulation can also occur through interactions with human users or other agents, where adversaries exploit trust or communication channels to influence the AI agent’s decisions.
Understanding these manipulation threats is crucial for developing effective defenses. It requires a comprehensive approach that considers the entire lifecycle of AI agents—from data collection and training to deployment and interaction with the environment. By anticipating how adversaries might exploit weaknesses, developers can design more robust and secure AI systems that maintain integrity even under attack.
Adversarial Attacks Explained
Adversarial attacks represent a sophisticated and growing threat to AI agents, exploiting their vulnerabilities by introducing carefully crafted inputs that cause the agent to make incorrect or unexpected decisions. These attacks are particularly concerning because they often involve imperceptible changes to data that can drastically alter the agent’s behavior without obvious signs of tampering.
At the core of adversarial attacks are adversarial examples—inputs intentionally designed to deceive AI models. For instance, in image recognition systems, an adversarial example might be a slightly altered image that looks normal to humans but causes the AI agent to misclassify it completely. This phenomenon arises because AI models, especially deep neural networks, rely on complex patterns in data that can be subtly manipulated.
There are several types of adversarial attacks:
Evasion Attacks:
These occur during the agent’s operational phase, where attackers modify inputs to evade detection or cause misclassification. For example, an attacker might alter malware code just enough to bypass an AI-based security scanner.
Poisoning Attacks:
These target the training process by injecting malicious data into the training set, leading the AI agent to learn incorrect patterns or biases. This can degrade the agent’s performance or cause it to behave maliciously.
Model Extraction and Inference Attacks:
Attackers attempt to reverse-engineer or infer sensitive information about the AI model, such as its parameters or training data, which can then be used to craft more effective adversarial inputs.
Physical Adversarial Attacks:
In real-world scenarios, adversaries can create physical objects or modifications—like stickers on stop signs—that fool AI agents in autonomous vehicles or surveillance systems.
Vulnerabilities in AI Agent Architectures
AI agents, while powerful and versatile, possess inherent vulnerabilities within their architectures that can be exploited by attackers. Understanding these weaknesses is critical for designing secure and resilient systems.
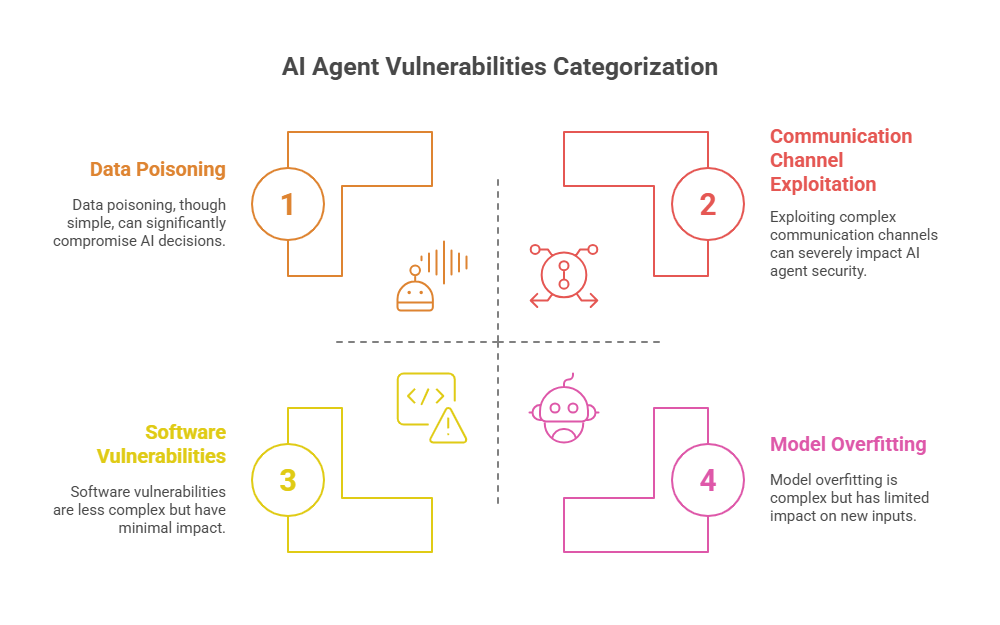
Complexity and Opacity:
Many AI agents, especially those based on deep learning, operate as “black boxes” with complex internal representations that are difficult to interpret. This opacity makes it challenging to detect when an agent is under attack or behaving abnormally, providing attackers with opportunities to exploit hidden weaknesses.
Dependence on Data Quality:
AI agents rely heavily on the quality and integrity of their training data. If the data is biased, incomplete, or manipulated (e.g., through poisoning attacks), the agent’s decisions can be compromised. This dependency creates a vulnerability at the data collection and preprocessing stages.
Model Overfitting and Generalization Issues:
Agents that overfit to training data may perform poorly on new or adversarial inputs. Attackers can exploit this by presenting inputs that fall outside the agent’s learned distribution, causing unpredictable or erroneous behavior.
Limited Robustness to Adversarial Inputs:
Many AI models are sensitive to small perturbations in input data. This sensitivity allows adversaries to craft adversarial examples that mislead the agent without obvious signs of tampering.
Communication and Interaction Channels:
AI agents often interact with other agents, users, or external systems. These communication channels can be exploited for injection of malicious commands, misinformation, or social engineering attacks.
Software and Hardware Vulnerabilities:
Beyond the AI model itself, the underlying software frameworks, libraries, and hardware platforms may contain security flaws. Exploiting these can allow attackers to manipulate the agent’s operation or gain unauthorized access.
Detection and Defense Strategies
Protecting AI agents from security threats requires effective detection and defense strategies tailored to their unique vulnerabilities. These strategies aim to identify attacks early, mitigate their impact, and enhance the overall robustness of AI systems.
Anomaly Detection:
One of the primary methods for detecting attacks is monitoring the AI agent’s inputs and outputs for unusual patterns or behaviors. Techniques such as statistical analysis, clustering, and machine learning-based anomaly detectors can flag suspicious activities that deviate from normal operation.
Adversarial Training:
This defense involves augmenting the training data with adversarial examples, enabling the AI agent to recognize and resist malicious inputs. By exposing the model to potential attacks during training, it becomes more robust against evasion attempts.
Input Sanitization and Validation:
Preprocessing inputs to remove noise, inconsistencies, or suspicious modifications can reduce the risk of adversarial manipulation. Techniques include filtering, normalization, and using multiple sensors or data sources for cross-validation.
Model Robustness Enhancements:
Developing AI architectures that are inherently less sensitive to small input perturbations helps defend against adversarial attacks. Approaches include using regularization methods, defensive distillation, and robust optimization techniques.
Secure Data Management:
Ensuring the integrity and authenticity of training data through secure collection, storage, and access controls helps prevent poisoning attacks. Employing cryptographic methods and audit trails can enhance data security.
Behavioral Monitoring and Logging:
Continuous monitoring of AI agent behavior, combined with detailed logging, allows for post-attack analysis and forensic investigation. This helps in understanding attack vectors and improving future defenses.
Multi-Agent and Redundancy Approaches:
Using multiple AI agents with diverse models or strategies can provide cross-checks and reduce the risk of a single point of failure. Redundancy increases resilience against targeted attacks.
Human-in-the-Loop Systems:
Incorporating human oversight in critical decision-making processes ensures that suspicious or high-risk actions by AI agents are reviewed before execution, adding an additional layer of security.
Defense Mechanisms and Robustness Strategies
As AI agents become more integrated into critical systems, hardening them against attacks is essential. Defense mechanisms and robustness strategies are designed to minimize vulnerabilities and ensure reliable agent performance, even in adversarial environments.
Adversarial Training:
One of the most effective ways to increase robustness is adversarial training, where the model is exposed to adversarial examples during training. This helps the agent learn to recognize and resist malicious inputs.
Input Validation and Sanitization:
Before processing, all inputs should be checked for anomalies or suspicious patterns. This reduces the risk of adversarial manipulation and data poisoning.
Ensemble Methods:
Using multiple models or agents to make decisions can increase resilience. If one model is compromised, others can provide a sanity check, reducing the risk of a successful attack.
Defensive Distillation:
This technique involves training a model to output softened probabilities, making it harder for attackers to craft effective adversarial examples.
Regularization and Robust Optimization:
Applying regularization techniques and robust optimization during training can help models generalize better and resist overfitting to adversarial data.
Monitoring and Logging:
Continuous monitoring of agent behavior and detailed logging can help detect attacks early and provide valuable data for post-incident analysis.
Example: Simple Adversarial Training in Python
Below is a simplified Python example demonstrating adversarial training for a binary classifier using scikit-learn. The code generates adversarial examples by adding small noise to the data and retrains the model to improve robustness.
python
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score
# Generate synthetic data
X, y = make_classification(n_samples=500, n_features=2, n_informative=2, n_redundant=0, random_state=42)
# Train initial model
model = LogisticRegression()
model.fit(X, y)
print("Initial accuracy:", accuracy_score(y, model.predict(X)))
# Create adversarial examples (add small noise)
epsilon = 0.2
X_adv = X + epsilon * np.sign(np.random.randn(*X.shape))
# Combine original and adversarial data
X_combined = np.vstack([X, X_adv])
y_combined = np.hstack([y, y])
# Retrain model with adversarial training
model_adv = LogisticRegression()
model_adv.fit(X_combined, y_combined)
print("Accuracy after adversarial training:", accuracy_score(y, model_adv.predict(X)))This code demonstrates a basic approach to adversarial training: by exposing the model to both clean and perturbed data, it becomes more robust to small, adversarial changes in input. In real-world applications, more sophisticated adversarial example generation and defense techniques are used, but the principle remains the same—proactively preparing AI agents for the challenges posed by adversarial environments.
Secure Training and Data Integrity
Ensuring the security and integrity of training data is fundamental to building trustworthy AI agents. Since AI models heavily depend on the quality and authenticity of their training datasets, any compromise during data collection, storage, or processing can lead to degraded performance, biased decisions, or even malicious behavior.
Data Provenance and Verification:
Tracking the origin and history of data helps verify its authenticity. Techniques such as cryptographic hashing and digital signatures can ensure that data has not been tampered with during transmission or storage.
Secure Data Collection:
Implementing secure channels and protocols for data acquisition prevents unauthorized access or injection of malicious data. This is especially important when data is collected from multiple or untrusted sources.
Data Sanitization and Preprocessing:
Before training, data should be cleaned and validated to remove noise, inconsistencies, or potentially poisoned samples. Automated anomaly detection tools can assist in identifying suspicious data points.
Robust Training Protocols:
Training processes should include mechanisms to detect and mitigate poisoning attacks. This can involve techniques like differential privacy, which limits the influence of any single data point, or robust statistics that reduce sensitivity to outliers.
Access Control and Auditing:
Restricting access to training data and maintaining detailed logs of data usage help prevent insider threats and enable forensic analysis in case of security incidents.
Federated Learning and Secure Aggregation:
In distributed training scenarios, federated learning allows models to be trained across multiple devices without sharing raw data, enhancing privacy and reducing the risk of data leakage. Secure aggregation protocols ensure that updates from participants are combined without exposing individual data contributions.
Real-World Case Studies of AI Agent Attacks
Examining real-world attacks on AI agents provides valuable insights into vulnerabilities, attack methods, and effective defenses. These case studies highlight the practical challenges faced when securing intelligent systems and offer lessons for future development.
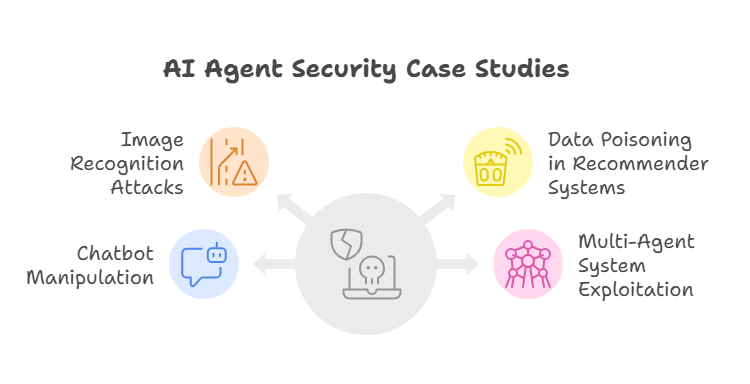
Case Study 1: Adversarial Attacks on Image Recognition Systems
In 2018, researchers demonstrated that small, imperceptible perturbations to images could cause AI agents in autonomous vehicles to misclassify traffic signs, such as interpreting a stop sign as a speed limit sign. This attack exploited the sensitivity of deep learning models to adversarial inputs, raising concerns about safety in real-world deployments.
Lesson: Robustness to adversarial examples is critical, especially in safety-critical applications. Defensive training and input validation are necessary to mitigate such risks.
Case Study 2: Data Poisoning in Recommender Systems
A popular online platform experienced a data poisoning attack where malicious users injected fake reviews and ratings to manipulate the recommendations generated by AI agents. This led to biased suggestions and degraded user trust.
Lesson: Secure data collection and anomaly detection mechanisms are essential to prevent manipulation of training data and maintain system integrity.
Case Study 3: Manipulation of Chatbots and Virtual Assistants
Attackers exploited vulnerabilities in natural language processing agents by crafting inputs that triggered inappropriate or harmful responses. These attacks leveraged the agents’ inability to fully understand context or filter malicious content.
Lesson: Incorporating content filtering, context awareness, and human oversight can reduce the risk of harmful agent behavior.
Case Study 4: Exploiting Multi-Agent Systems in Finance
In algorithmic trading, coordinated attacks targeted AI agents managing portfolios by feeding misleading market signals. This caused agents to make suboptimal trades, resulting in financial losses.
Lesson: Monitoring agent interactions and implementing cross-agent verification can help detect and prevent coordinated adversarial actions.
Regulatory and Ethical Considerations
The deployment of AI agents, especially in security-sensitive contexts, raises important regulatory and ethical questions. Legal frameworks worldwide are evolving to address the unique challenges posed by AI, aiming to ensure that these technologies are developed and used responsibly.
Regulations such as the European Union’s AI Act emphasize risk-based approaches, requiring transparency, accountability, and human oversight for high-risk AI systems. Data privacy laws like GDPR and CCPA impose strict requirements on how AI agents handle personal information, mandating consent, data minimization, and protection.
Ethically, AI agents must be designed to avoid biases, ensure fairness, and maintain transparency in decision-making. Developers have a responsibility to create systems that respect user rights, prevent discrimination, and provide explainable outcomes. The integration of AI agents into critical systems necessitates ongoing ethical review and stakeholder engagement to align technology with societal values.
Future Trends in AI Agent Security
AI agent security is a rapidly evolving field, with emerging technologies and research focusing on enhancing robustness, transparency, and trustworthiness. Future trends include the development of explainable AI models that provide clear rationales for decisions, advanced adversarial defense mechanisms, and federated learning approaches that protect data privacy during model training.
The integration of AI agents with blockchain for secure audit trails, the use of quantum-resistant cryptographic techniques, and the rise of autonomous self-healing systems are also on the horizon. These advancements aim to create AI agents that are resilient against sophisticated attacks and compliant with evolving regulatory standards.
Best Practices for Developers and Organizations
To implement secure AI agent systems, developers and organizations should adopt best practices including:
Conducting thorough risk assessments and threat modeling.
Ensuring data quality, integrity, and privacy throughout the AI lifecycle.
Implementing robust authentication, authorization, and encryption mechanisms.
Incorporating explainability and transparency features.
Establishing continuous monitoring and incident response plans.
Providing training and awareness programs for stakeholders.
Engaging in ethical AI development and compliance with legal frameworks.
From Pull Request to Deployment: AI Agents in the Review Process

