
Introduction: The New Era of Intelligent Applications
The world of software development is undergoing a profound transformation. Traditional applications, once limited to executing predefined instructions, are now evolving into intelligent systems capable of learning, adapting, and making decisions. At the heart of this revolution are AI agents—autonomous software components that bring a new level of intelligence and flexibility to modern applications.
AI agents are not just another trend; they represent a fundamental shift in how we think about building software. Instead of hard-coding every possible scenario, developers can now create applications that understand context, analyze data in real time, and respond dynamically to user needs. This means smarter recommendations, more natural interactions, and solutions that continuously improve as they gather more data.
The rise of AI agents is making intelligent application development more accessible than ever. Thanks to open-source frameworks, cloud-based AI services, and user-friendly tools, even small teams can integrate advanced AI capabilities into their products. Whether it’s a chatbot that understands natural language, a recommendation engine that personalizes content, or an automation agent that optimizes business processes—AI agents are changing the rules of the game.
In this new era, the focus shifts from simply building functional software to creating applications that truly understand and anticipate user needs. Developers are empowered to solve complex problems with less effort, while users benefit from more intuitive, responsive, and personalized experiences.
As we explore the world of AI agents in the following chapters, you’ll discover how these technologies are reshaping the landscape of application development—and how you can harness their power to build intelligent applications with ease.
What Are AI Agents? Key Concepts and Definitions
AI agents are autonomous software entities designed to perceive their environment, process information, and take actions to achieve specific goals. Unlike traditional programs that follow a fixed set of instructions, AI agents can adapt their behavior based on changing conditions and new data.
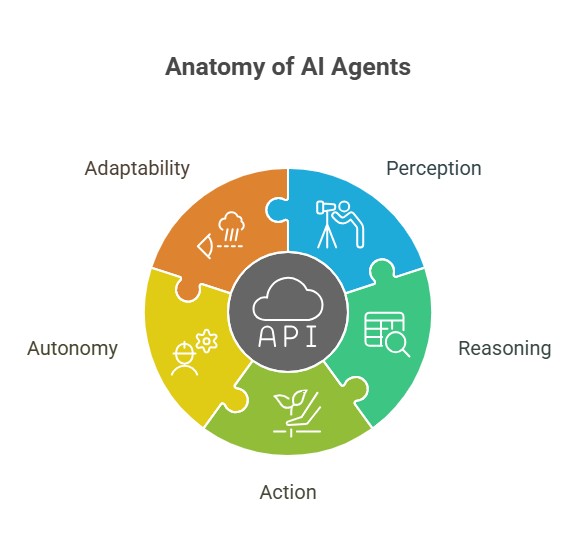
At the core, an AI agent consists of three main components: perception, reasoning, and action. Perception allows the agent to gather information from its environment—this could be user input, sensor data, or information from other systems. Reasoning is where the agent analyzes this data, often using machine learning or rule-based logic, to make decisions. Finally, the action component enables the agent to interact with its environment, whether by sending a message, updating a database, or controlling a device.
There are different types of AI agents, each suited to specific tasks. Simple agents might follow basic rules to automate repetitive tasks, while more advanced agents use deep learning to understand natural language or recognize patterns in complex data. Some agents are reactive, responding immediately to changes, while others are proactive, anticipating needs and planning ahead.
A key concept in the world of AI agents is autonomy. This means that agents can operate independently, without constant human supervision. They can learn from experience, adapt to new situations, and even collaborate with other agents or humans to solve problems more efficiently.
In summary, AI agents are intelligent, adaptable, and autonomous components that bring a new dimension to application development. By understanding their key concepts and capabilities, developers can unlock powerful new ways to build smarter, more responsive software.
Why Use AI Agents in Application Development?
The integration of AI agents into application development is rapidly becoming a game-changer for both developers and end users. But what makes AI agents so valuable, and why are they increasingly chosen as a foundation for modern software solutions?
First and foremost, AI agents bring adaptability and intelligence to applications. Unlike traditional code, which requires explicit instructions for every scenario, AI agents can analyze data, learn from user interactions, and adjust their behavior in real time. This means applications can offer smarter recommendations, automate complex workflows, and respond dynamically to changing conditions—without constant manual updates from developers.
Another key advantage is efficiency. AI agents can automate repetitive or time-consuming tasks, freeing up developers and users to focus on more creative or strategic work. For example, an AI agent can handle customer support queries, monitor system health, or optimize resource allocation, all with minimal human intervention. This not only speeds up processes but also reduces the risk of human error.
Personalization is also a major benefit. AI agents can analyze user preferences and behaviors to deliver tailored experiences, whether it’s suggesting relevant content, customizing interfaces, or predicting user needs before they arise. This level of personalization leads to higher user satisfaction and engagement.
From a business perspective, AI agents can drive innovation and competitiveness. They enable organizations to quickly adapt to market changes, scale their operations efficiently, and unlock new opportunities through data-driven insights. As AI technologies become more accessible, even small teams can leverage powerful tools that were once reserved for large enterprises.
In summary, using AI agents in application development means building smarter, more flexible, and more user-centric software. They empower developers to solve complex problems with less effort and help businesses deliver value faster and more effectively. As the technology continues to evolve, AI agents are set to become an essential part of every modern application.
Choosing the Right Tools and Frameworks for AI Agents
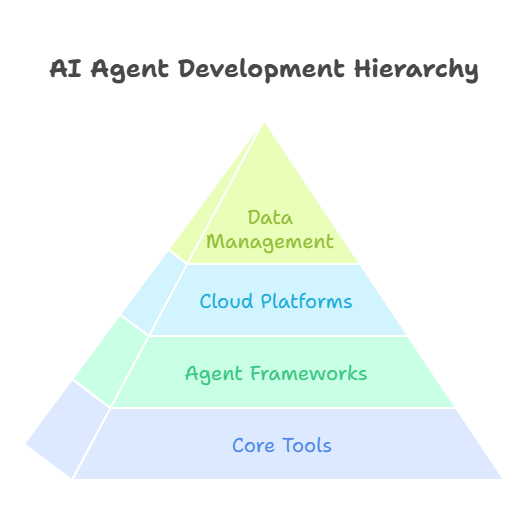
Selecting the right tools and frameworks is a crucial step in building effective AI agents. The landscape of AI development is rich and diverse, offering solutions tailored to different needs, levels of expertise, and project requirements.
For most developers, Python remains the language of choice for AI agent development. Its extensive ecosystem includes libraries for machine learning (like scikit-learn, TensorFlow, and PyTorch), natural language processing (such as spaCy and NLTK), and agent-based modeling (for example, Mesa). These libraries provide robust building blocks for creating, training, and deploying intelligent agents.
When it comes to frameworks specifically designed for agent-based systems, options like SPADE and JADE stand out. SPADE is a Python-based framework that simplifies the creation of multi-agent systems, supporting communication, coordination, and distributed deployment. JADE, on the other hand, is a mature Java platform widely used in research and industry for building scalable agent systems.
For cloud-based AI, platforms like Google Cloud AI, AWS SageMaker, and Microsoft Azure AI offer managed services that streamline the process of training, deploying, and scaling AI agents. These platforms provide powerful infrastructure, pre-built models, and integration with other cloud services, making it easier to bring intelligent agents into production environments.
It’s also important to consider tools for data management, experiment tracking, and model monitoring. Solutions like MLflow, Weights & Biases, and DVC help teams track experiments, version data, and monitor agent performance over time, ensuring reliability and reproducibility.
Ultimately, the best choice of tools and frameworks depends on your project’s goals, the complexity of the agents, and your team’s expertise. By leveraging the right technologies, you can accelerate development, reduce complexity, and ensure your AI agents are robust, scalable, and ready for real-world challenges.
Designing User-Centric Intelligent Applications
Building intelligent applications isn’t just about implementing advanced algorithms or deploying powerful AI agents—it’s about creating solutions that genuinely serve users’ needs. User-centric design ensures that technology adapts to people, not the other way around.
The first step in designing user-centric intelligent applications is understanding your users. This means going beyond basic demographics and delving into their goals, pain points, and daily workflows. Techniques like user interviews, surveys, and journey mapping can reveal valuable insights that guide the design of AI-driven features.
Once you understand your users, it’s important to focus on transparency and trust. Intelligent applications should clearly communicate how and why decisions are made, especially when AI agents are involved. Features like explainable recommendations, feedback mechanisms, and the ability to override automated actions help users feel in control and confident in the system.
Personalization is another key aspect. AI agents excel at analyzing user behavior and preferences to deliver tailored experiences—whether it’s suggesting relevant content, adapting interfaces, or automating routine tasks. However, personalization should always respect user privacy and provide clear options for managing data and preferences.
Usability testing is essential throughout the development process. Prototyping, A/B testing, and gathering real user feedback allow teams to refine AI-driven features and ensure they truly enhance the user experience. Iterative design helps catch issues early and adapt to changing user expectations.
Finally, accessibility should never be overlooked. Intelligent applications should be inclusive, offering intuitive interfaces and support for users with diverse needs and abilities. This not only broadens your audience but also demonstrates a commitment to ethical and responsible AI.
In summary, designing user-centric intelligent applications means putting people at the heart of every decision. By combining deep user understanding with the power of AI agents, developers can create solutions that are not only smart, but also intuitive, trustworthy, and genuinely helpful.
Integrating AI Agents into Existing Systems
Integrating AI agents into existing systems is a strategic way to enhance the intelligence and capabilities of your current applications without the need for a complete rebuild. However, successful integration requires careful planning, a clear understanding of your system’s architecture, and a focus on seamless user experience.
The first step is to identify where AI agents can add the most value. This might be automating repetitive tasks, improving decision-making with data-driven insights, or enhancing user interactions through natural language processing. By targeting specific pain points or opportunities, you can ensure that the integration delivers tangible benefits.
Next, consider the technical architecture. AI agents can be integrated as standalone microservices, embedded directly into application code, or connected via APIs. Microservices are often the preferred approach, as they allow for modular development, independent scaling, and easier maintenance. Using APIs enables your AI agents to communicate with other parts of the system, exchange data, and trigger actions as needed.
Data integration is another critical aspect. AI agents rely on access to relevant, high-quality data to function effectively. This may require connecting to existing databases, data warehouses, or real-time data streams. Ensuring data consistency, security, and privacy is essential, especially when dealing with sensitive information.
Testing and monitoring are key to a smooth integration. Before deploying AI agents in production, it’s important to test their performance in real-world scenarios and monitor their behavior over time. This helps catch potential issues early and ensures that the agents continue to deliver value as the system evolves.
Finally, don’t forget about user experience. The introduction of AI agents should feel natural and intuitive for users. Clear communication, helpful onboarding, and the ability to provide feedback or override automated actions all contribute to building trust and acceptance. In summary, integrating AI agents into existing systems is a powerful way to modernize your applications and unlock new capabilities. With thoughtful planning and a focus on both technical and human factors, you can ensure a successful transition to more intelligent, responsive software.
Data Preparation and Management for AI Agents
Data is the foundation of every intelligent application. For AI agents to deliver accurate, relevant, and trustworthy results, they need access to high-quality, well-prepared data. Effective data preparation and management are therefore essential steps in any AI-driven project.
The process begins with data collection. This involves gathering information from various sources, such as databases, user interactions, sensors, or external APIs. It’s important to ensure that the data is representative of real-world scenarios and covers the range of situations the AI agent might encounter.
Once collected, data must be cleaned and preprocessed. This step includes handling missing values, removing duplicates, correcting errors, and standardizing formats. Clean data reduces noise and helps AI agents learn more effectively, leading to better performance in production.
Feature engineering is another crucial aspect. This means transforming raw data into meaningful inputs that the AI agent can use. For example, extracting keywords from text, normalizing numerical values, or creating new variables that capture important relationships. Well-designed features can significantly boost the effectiveness of AI models.
Data management doesn’t end with preparation. Ongoing processes like data versioning, secure storage, and access control are vital for maintaining data integrity and compliance. Tools such as DVC (Data Version Control) or cloud-based data platforms help teams track changes, collaborate efficiently, and ensure that models are always trained on the correct datasets.
Finally, privacy and security must be prioritized. Sensitive data should be anonymized or encrypted, and access should be restricted to authorized users only. Compliance with regulations like GDPR or HIPAA is not just a legal requirement—it’s also key to building user trust.
In summary, thoughtful data preparation and management are the backbone of successful AI agents. By investing time and resources in these areas, developers can ensure their intelligent applications are reliable, accurate, and ready to deliver real value.
Training, Testing, and Deploying AI Agents
The journey from concept to production-ready AI agent involves three critical phases: training, testing, and deployment. Each phase requires careful attention to ensure that your intelligent application performs reliably in real-world scenarios.
Training Phase
Training is where your AI agent learns from data to develop its capabilities. This process involves selecting appropriate algorithms, tuning hyperparameters, and iterating until the model achieves satisfactory performance. The key is to use representative training data and validate results using proper metrics.
Testing Phase
Testing ensures that your AI agent behaves correctly across different scenarios. This includes unit testing for individual components, integration testing for system interactions, and performance testing under various loads. Testing should also evaluate the agent’s decision-making process and edge case handling.
Deployment Phase
Deployment brings your AI agent into production, where it can serve real users. This involves setting up infrastructure, monitoring systems, and establishing processes for updates and maintenance. Modern deployment often uses containerization and cloud services for scalability and reliability.
Here’s a practical Python example demonstrating a complete pipeline:
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
import joblib
import logging
from datetime import datetime
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class AIAgentPipeline:
def __init__(self):
self.model = None
self.is_trained = False
def prepare_data(self, data_path):
"""Load and prepare training data"""
logger.info("Loading and preparing data...")
# Load data (example with synthetic data)
np.random.seed(42)
n_samples = 1000
# Generate synthetic features
X = np.random.randn(n_samples, 4)
y = (X[:, 0] + X[:, 1] > 0).astype(int)
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
logger.info(f"Data prepared: {len(X_train)} training samples, {len(X_test)} test samples")
return X_train, X_test, y_train, y_test
def train_agent(self, X_train, y_train):
"""Train the AI agent"""
logger.info("Training AI agent...")
self.model = RandomForestClassifier(
n_estimators=100,
random_state=42,
max_depth=10
)
self.model.fit(X_train, y_train)
self.is_trained = True
logger.info("Training completed successfully")
def test_agent(self, X_test, y_test):
"""Test the AI agent performance"""
if not self.is_trained:
raise ValueError("Agent must be trained before testing")
logger.info("Testing AI agent...")
# Make predictions
y_pred = self.model.predict(X_test)
# Calculate metrics
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
logger.info(f"Test accuracy: {accuracy:.3f}")
logger.info(f"Classification report:\n{report}")
return accuracy, report
def deploy_agent(self, model_path="ai_agent_model.pkl"):
"""Deploy the AI agent by saving the model"""
if not self.is_trained:
raise ValueError("Agent must be trained before deployment")
logger.info("Deploying AI agent...")
# Save model
joblib.dump(self.model, model_path)
# Save metadata
metadata = {
'deployment_time': datetime.now().isoformat(),
'model_type': 'RandomForestClassifier',
'version': '1.0'
}
with open('model_metadata.txt', 'w') as f:
for key, value in metadata.items():
f.write(f"{key}: {value}\n")
logger.info(f"Model deployed successfully to {model_path}")
return model_path
def predict(self, input_data):
"""Make predictions with the deployed agent"""
if not self.is_trained:
raise ValueError("Agent must be trained before making predictions")
prediction = self.model.predict(input_data)
confidence = self.model.predict_proba(input_data).max(axis=1)
return prediction, confidence
# Example usage
def main():
# Initialize pipeline
pipeline = AIAgentPipeline()
# Prepare data
X_train, X_test, y_train, y_test = pipeline.prepare_data("data.csv")
# Train agent
pipeline.train_agent(X_train, y_train)
# Test agent
accuracy, report = pipeline.test_agent(X_test, y_test)
# Deploy agent
model_path = pipeline.deploy_agent()
# Test prediction
sample_input = np.array([[1.0, -0.5, 0.3, 0.8]])
prediction, confidence = pipeline.predict(sample_input)
logger.info(f"Sample prediction: {prediction[0]} (confidence: {confidence[0]:.3f})")
print("AI Agent pipeline completed successfully!")
print(f"Model saved to: {model_path}")
if __name__ == "__main__":
main()
# Created/Modified files during execution:
print("ai_agent_model.pkl")
print("model_metadata.txt")This comprehensive pipeline demonstrates the complete lifecycle of an AI agent, from data preparation through deployment. The code includes proper logging, error handling, and metadata tracking—essential components for production-ready systems.
Real-World Use Cases: AI Agents in Action
AI agents are no longer just a concept from research papers—they are actively transforming industries and everyday experiences. Their ability to learn, adapt, and automate complex tasks makes them invaluable across a wide range of real-world scenarios.
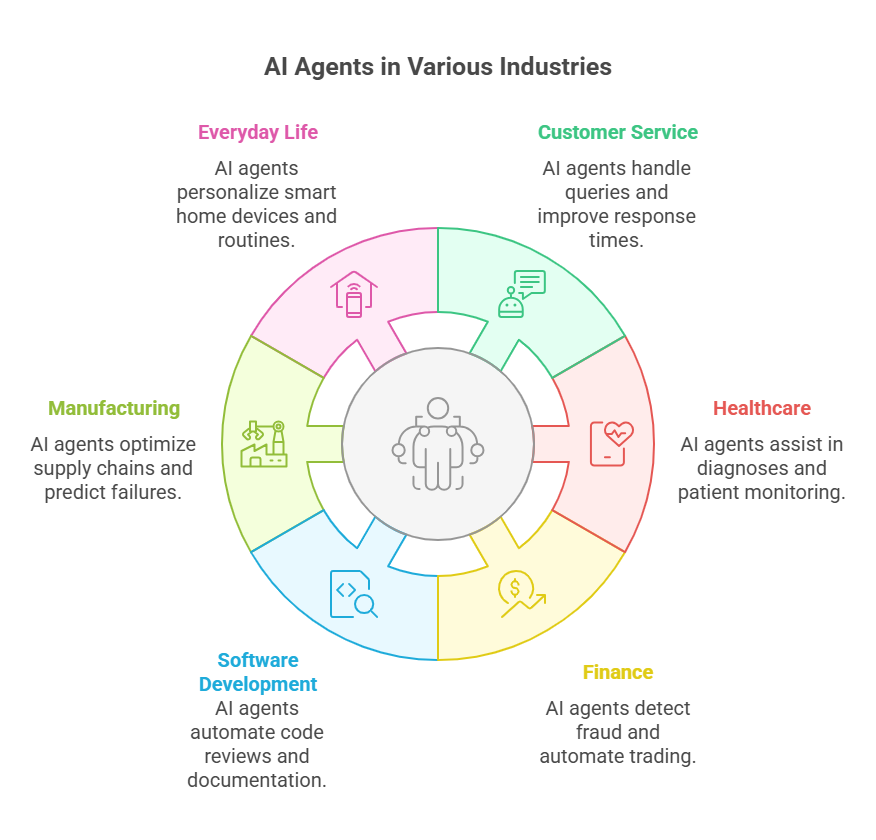
In customer service, AI agents power intelligent chatbots and virtual assistants that handle thousands of queries simultaneously. These agents can understand natural language, provide instant answers, and even escalate complex issues to human operators when needed. This not only improves response times but also enhances customer satisfaction and reduces operational costs.
In healthcare, AI agents assist doctors by analyzing medical images, monitoring patient data, and predicting potential health risks. For example, an AI agent can flag abnormal patterns in X-rays or alert medical staff to early signs of deterioration in a patient’s condition. This leads to faster diagnoses and more proactive care.
The financial sector benefits from AI agents that detect fraudulent transactions, automate trading, and personalize financial advice. These agents analyze vast amounts of data in real time, spotting anomalies or opportunities that would be impossible for humans to process manually.
In software development, AI agents help automate code reviews, generate documentation, and even suggest bug fixes. By integrating with development tools, they streamline workflows and allow programmers to focus on creative problem-solving rather than repetitive tasks.
Manufacturing and logistics also leverage AI agents for predictive maintenance, supply chain optimization, and quality control. Agents can monitor equipment, predict failures before they happen, and optimize delivery routes to save time and resources.
Even in everyday life, AI agents are present in smart home devices, personal assistants, and recommendation systems. They learn user preferences, automate routines, and make technology more intuitive and responsive.
These examples illustrate just a fraction of what’s possible. As AI agents continue to evolve, their impact will only grow—enabling smarter, more efficient, and more personalized solutions in virtually every field.
Best Practices for Collaboration Between Developers and Data Scientists
Building intelligent applications with AI agents requires seamless collaboration between developers and data scientists. These two roles bring different perspectives, skills, and priorities to the table, making effective teamwork essential for project success.
Establish Clear Communication Channels
The foundation of successful collaboration is open, regular communication. Teams should establish shared vocabulary, hold regular sync meetings, and use collaborative tools like Slack, Microsoft Teams, or project management platforms. Clear documentation of requirements, model specifications, and system architecture helps prevent misunderstandings.
Define Roles and Responsibilities Early
While there’s natural overlap between development and data science, it’s important to clarify who owns what. Typically, data scientists focus on model development, feature engineering, and performance optimization, while developers handle system integration, deployment, and infrastructure. However, both should understand each other’s domains.
Use Shared Development Environments
Tools like Jupyter notebooks, Docker containers, and cloud-based platforms enable both teams to work in consistent environments. Version control systems like Git should be used not just for code, but also for datasets, model configurations, and experiment tracking.
Implement Continuous Integration for ML
Just as developers use CI/CD pipelines, AI projects benefit from MLOps practices. This includes automated testing of models, data validation, and deployment pipelines that both teams can understand and contribute to.
Focus on Reproducibility
All experiments, data transformations, and model training should be reproducible. This means documenting dependencies, using fixed random seeds, and maintaining clear records of data sources and preprocessing steps.
Here’s a practical example of collaborative workflow using Python:
python
import mlflow
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import logging
# Shared logging configuration
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class CollaborativeMLPipeline:
"""
A pipeline designed for collaboration between developers and data scientists
"""
def __init__(self, experiment_name="ai_agent_development"):
# Set up MLflow for experiment tracking
mlflow.set_experiment(experiment_name)
self.experiment_name = experiment_name
def log_experiment(self, model, X_test, y_test, params, run_name=None):
"""
Log experiment results for both developers and data scientists to track
"""
with mlflow.start_run(run_name=run_name):
# Log parameters (useful for data scientists)
mlflow.log_params(params)
# Make predictions and calculate metrics
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
# Log metrics (useful for both teams)
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("test_samples", len(X_test))
# Log model (useful for developers for deployment)
mlflow.sklearn.log_model(model, "model")
logger.info(f"Experiment logged: {run_name}, Accuracy: {accuracy:.3f}")
return accuracy
def validate_data_quality(self, data):
"""
Data validation function that both teams can understand and use
"""
validation_results = {
"total_rows": len(data),
"missing_values": data.isnull().sum().sum(),
"duplicate_rows": data.duplicated().sum(),
"data_types": data.dtypes.to_dict()
}
# Log validation results
logger.info("Data Quality Report:")
for key, value in validation_results.items():
logger.info(f" {key}: {value}")
# Alert if data quality issues found
if validation_results["missing_values"] > 0:
logger.warning(f"Found {validation_results['missing_values']} missing values")
if validation_results["duplicate_rows"] > 0:
logger.warning(f"Found {validation_results['duplicate_rows']} duplicate rows")
return validation_results
def create_model_api_spec(self, model, feature_names):
"""
Generate API specification for developers to implement
"""
api_spec = {
"model_type": type(model).__name__,
"input_features": feature_names,
"feature_count": len(feature_names),
"output_type": "classification",
"prediction_method": "predict",
"probability_method": "predict_proba"
}
logger.info("Model API Specification:")
for key, value in api_spec.items():
logger.info(f" {key}: {value}")
return api_spec
# Example collaborative workflow
def collaborative_workflow():
"""
Example workflow showing collaboration between developers and data scientists
"""
# Initialize collaborative pipeline
pipeline = CollaborativeMLPipeline("team_collaboration_demo")
# Generate sample data (normally loaded by data scientists)
import numpy as np
np.random.seed(42)
# Create synthetic dataset
n_samples = 1000
feature_names = ['feature_1', 'feature_2', 'feature_3', 'feature_4']
X = pd.DataFrame(
np.random.randn(n_samples, len(feature_names)),
columns=feature_names
)
y = (X['feature_1'] + X['feature_2'] > 0).astype(int)
# Data validation (shared responsibility)
data_quality = pipeline.validate_data_quality(X)
# Split data (data science task)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Model training with different configurations (data science focus)
configurations = [
{"n_estimators": 50, "max_depth": 5},
{"n_estimators": 100, "max_depth": 10},
{"n_estimators": 200, "max_depth": 15}
]
best_accuracy = 0
best_model = None
for i, config in enumerate(configurations):
# Train model
model = RandomForestClassifier(**config, random_state=42)
model.fit(X_train, y_train)
# Log experiment (shared tracking)
accuracy = pipeline.log_experiment(
model, X_test, y_test, config,
run_name=f"config_{i+1}"
)
# Track best model
if accuracy > best_accuracy:
best_accuracy = accuracy
best_model = model
# Generate API specification for developers
api_spec = pipeline.create_model_api_spec(best_model, feature_names)
logger.info(f"Best model accuracy: {best_accuracy:.3f}")
logger.info("Collaboration workflow completed successfully!")
return best_model, api_spec
# Run collaborative workflow
if __name__ == "__main__":
model, spec = collaborative_workflow()
print("Collaborative ML pipeline completed!")
# Created/Modified files during execution:
print("mlruns/") # MLflow tracking directoryKey Collaboration Principles:
Shared Ownership: Both teams should feel responsible for the final product’s success
Regular Reviews: Schedule frequent code and model reviews involving both teams
Documentation: Maintain clear documentation that serves both technical and business stakeholders
Testing: Implement comprehensive testing that covers both model performance and system integration
Challenges and Solutions in Building AI-Driven Applications
Building AI-driven applications with intelligent agents opens up new possibilities, but it also introduces a unique set of challenges. Understanding these obstacles—and knowing how to address them—can make the difference between a successful project and one that falls short of its potential.
1. Data Quality and Availability
AI agents rely on high-quality, representative data. Incomplete, biased, or noisy datasets can lead to poor model performance and unreliable outcomes. The solution is to invest in robust data collection, cleaning, and validation processes. Regular audits and the use of automated data quality tools help ensure that your agents learn from accurate and relevant information.
2. Model Interpretability and Trust
As AI agents make more decisions, users and stakeholders need to understand how those decisions are made. Black-box models can erode trust, especially in sensitive domains like healthcare or finance. To address this, use explainable AI techniques—such as feature importance analysis, SHAP values, or LIME—to provide transparency and build user confidence.
3. Integration with Legacy Systems
Many organizations have existing systems that weren’t designed with AI in mind. Integrating new AI agents can be complex and risky. The best approach is to use modular architectures, such as microservices and APIs, which allow AI components to interact with legacy systems without major overhauls. Careful planning and incremental integration reduce disruption.
4. Scalability and Performance
AI agents may need to process large volumes of data or serve thousands of users simultaneously. Performance bottlenecks can arise if the system isn’t designed for scale. Solutions include leveraging cloud infrastructure, using distributed computing frameworks, and optimizing code for efficiency. Monitoring tools help identify and resolve performance issues early.
5. Security and Privacy
Handling sensitive data and making autonomous decisions introduces security and privacy risks. It’s essential to implement strong access controls, encrypt data in transit and at rest, and comply with relevant regulations (like GDPR or HIPAA). Regular security assessments and privacy-by-design principles help protect both users and organizations.
6. Continuous Learning and Maintenance
AI agents must adapt to changing environments and new data. Without ongoing monitoring and retraining, models can become outdated or biased. Establishing a process for continuous learning, automated retraining, and regular performance evaluation ensures that your AI agents remain effective over time.
7. Collaboration and Communication
Misalignment between developers, data scientists, and business stakeholders can slow progress or lead to suboptimal solutions. The answer is to foster a culture of collaboration, with clear communication channels, shared goals, and regular feedback loops.
Summary
While building AI-driven applications comes with real challenges, each has proven solutions. By focusing on data quality, transparency, modular integration, scalability, security, continuous improvement, and strong teamwork, you can overcome obstacles and unlock the full potential of intelligent agents in your projects.
Future Trends: The Evolving Role of AI Agents
The landscape of AI agents is rapidly evolving, driven by advances in technology, changing user expectations, and new business opportunities. Understanding these emerging trends is crucial for developers and organizations looking to stay ahead of the curve and build future-ready intelligent applications.
Generative AI Integration
The rise of large language models like GPT and other generative AI technologies is transforming how AI agents interact with users. Future agents will be capable of generating human-like text, creating visual content, and even writing code. This opens up possibilities for more natural conversations, automated content creation, and intelligent coding assistants that can understand context and generate solutions.
Multi-Modal Capabilities
Tomorrow’s AI agents won’t be limited to text or single data types. They’ll seamlessly process and combine information from multiple sources—text, images, audio, video, and sensor data. This multi-modal approach enables richer interactions and more comprehensive understanding of complex scenarios.
Autonomous Decision-Making
As AI agents become more sophisticated, they’ll take on greater autonomy in decision-making processes. From automated financial trading to self-managing IT infrastructure, agents will handle increasingly complex tasks with minimal human intervention. This shift requires robust safety mechanisms and ethical frameworks.
Edge Computing and Real-Time Processing
The future of AI agents lies not just in the cloud, but at the edge. Deploying agents on local devices and edge servers enables real-time processing, reduces latency, and improves privacy. This trend is particularly important for applications in autonomous vehicles, IoT devices, and mobile applications.
Collaborative Agent Ecosystems
Instead of working in isolation, future AI agents will collaborate in complex ecosystems. Multiple specialized agents will work together, sharing information and coordinating actions to solve problems that no single agent could handle alone. This distributed approach mirrors how human teams collaborate.
Explainable and Ethical AI
As AI agents take on more responsibility, the demand for transparency and ethical behavior grows. Future developments will focus on making agent decisions more interpretable, ensuring fairness, and building in ethical constraints. This includes bias detection, fairness metrics, and value-aligned decision-making.
Personalization at Scale
AI agents will become increasingly adept at understanding individual user preferences and contexts, delivering highly personalized experiences while maintaining privacy. Advanced techniques like federated learning will enable personalization without compromising data security.
Industry-Specific Specialization
We’ll see the emergence of highly specialized AI agents tailored to specific industries and use cases. Healthcare agents will understand medical terminology and protocols, legal agents will navigate complex regulations, and financial agents will master market dynamics.
Low-Code/No-Code AI Development
The democratization of AI continues with tools that allow non-technical users to create and deploy AI agents. Visual programming interfaces, pre-built components, and automated machine learning will make intelligent application development accessible to a broader audience.
Quantum-Enhanced AI
As quantum computing matures, it will enhance certain AI capabilities, particularly in optimization and pattern recognition. While still emerging, quantum-enhanced AI agents could solve problems that are currently computationally intractable.
Summary
The future of AI agents is bright and full of possibilities. These trends point toward more capable, autonomous, and collaborative intelligent systems that will transform how we work, live, and interact with technology. For developers and organizations, staying informed about these trends and experimenting with emerging technologies will be key to building the next generation of intelligent applications.
Conclusion: Making Intelligent Application Development Effortless
The journey through the world of AI agents reveals just how much the landscape of application development has changed. What once required vast resources and deep expertise is now within reach for teams of all sizes, thanks to the rapid evolution of tools, frameworks, and best practices dedicated to intelligent software.
AI agents have become the driving force behind smarter, more adaptive, and user-centric applications. By automating complex tasks, personalizing user experiences, and enabling real-time decision-making, they empower developers to focus on creativity and innovation rather than repetitive coding. The integration of AI agents into existing systems, combined with robust data management and collaborative workflows, ensures that intelligent features can be delivered efficiently and reliably.
Of course, building AI-driven applications is not without its challenges. Issues like data quality, model transparency, scalability, and security require thoughtful solutions and ongoing attention. However, as this guide has shown, there are proven strategies and tools to address each of these obstacles—making the path to intelligent applications smoother than ever before.
Looking ahead, the future of AI agents is filled with promise. With trends like generative AI, multi-modal capabilities, edge computing, and explainable AI on the horizon, the potential for innovation is virtually limitless. Developers who embrace these technologies and cultivate a user-first mindset will be well-positioned to create applications that not only meet today’s needs but also anticipate tomorrow’s opportunities.
In summary, intelligent application development is no longer a distant goal—it’s an achievable reality. By leveraging the power of AI agents, you can build solutions that are not just smart, but also intuitive, trustworthy, and truly effortless for users. The next era of software is here, and it’s powered by AI agents.
Autonomous AI Agents: From Theory to Practice
AI Agents in Practice: Automating a Programmer’s Daily Tasks

