
Introduction: What is Machine Learning and What is Deep Learning?
Modern artificial intelligence (AI) is based on two key approaches: Machine Learning (ML) and Deep Learning (DL). Although these terms are often used interchangeably, in reality they refer to different technologies and methods of data analysis.
Machine Learning is a field of computer science focused on creating algorithms and models that allow computers to learn from data without the need to program every rule by hand. In ML, a model analyzes input data, recognizes patterns, and makes decisions or predictions based on them. Examples of ML applications include recommendation systems, predictive analytics, fraud detection, and customer segmentation.
Deep Learning is a subfield of machine learning that uses multi-layered artificial neural networks to analyze very large and complex datasets. Deep Learning enables automatic feature extraction from data, making it particularly effective for tasks such as image recognition, natural language processing, or audio analysis. However, DL models require much larger amounts of data and computational power than traditional ML algorithms.
In summary, Machine Learning is a broad category encompassing various techniques for learning from data, while Deep Learning is its advanced branch that solves the most complex problems using deep neural networks. In the following sections of the article, we will take a closer look at how both approaches work, their differences, and practical applications.
Basic Principles of Machine Learning
Machine Learning (ML) is a process in which a computer learns from data to recognize patterns and make decisions without the need to program every rule by hand. In ML, training data, algorithms, and the model evaluation process play a key role.
Types of Machine Learning: Supervised, Unsupervised, Reinforcement
Supervised Learning: The model learns from data that contains both input features and known answers (labels). The goal is to teach the model to predict labels for new, unseen data. Examples: classifying emails as spam/not spam, predicting house prices.
Unsupervised Learning: The model analyzes data without known labels and independently discovers hidden patterns or groups. Examples: customer segmentation, anomaly detection, document clustering.
Reinforcement Learning: The model (agent) learns by interacting with the environment, receiving rewards or penalties for its actions. The goal is to maximize the total reward over time. Examples: computer games, robot control, process optimization.
Typical ML Algorithms and Their Applications
Linear and Logistic Regression: Used for predicting numerical values (regression) or binary classification (e.g., yes/no).
Decision Trees and Random Forests: Allow for classification and regression, are easy to interpret, and handle complex data structures well.
K-Nearest Neighbors (KNN): Classifies new data based on similarity to known examples.
Support Vector Machines (SVM): Effective for classifying data with a high number of features.
Clustering Algorithms (e.g., KMeans): Group data into sets with similar features without using labels.
Dimensionality Reduction (e.g., PCA): Enables data simplification and visualization of complex datasets.
Example: Iris classification using scikit-learn (Python)
python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Load data
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
# Train model
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Predict and evaluate accuracy
y_pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))Basic Principles of Deep Learning
Deep Learning is an advanced subfield of machine learning that uses multi-layered artificial neural networks to analyze and process large, complex datasets. Thanks to deep architectures, these models can automatically extract features from data, making them extremely effective for tasks such as image recognition, natural language processing, or audio analysis.
What are Neural Networks?
Artificial neural networks are structures inspired by the biological brain, built from layers of interconnected “neurons.” Each neuron processes input signals, performs simple calculations, and passes the result to subsequent layers. In deep neural networks, there are many hidden layers, allowing the model to learn increasingly complex data representations.
The basic types of layers in neural networks are:
Input layer – receives input data (e.g., image pixels, text vectors).
Hidden layers – process and transform data, learning abstract features.
Output layer – generates the final prediction or classification.
Deep Learning Architectures: CNN, RNN, LSTM, Transformer
Various neural network architectures are used in deep learning, tailored to the specifics of the task:
CNN (Convolutional Neural Networks) – convolutional networks, ideal for analyzing images and spatial data. They automatically detect features such as edges, shapes, or textures.
RNN (Recurrent Neural Networks) – recurrent networks for processing sequential data (e.g., text, time series). They can remember information from previous steps.
LSTM (Long Short-Term Memory) – a special type of RNN that handles long-term dependencies in sequences, often used in machine translation or speech recognition.
Transformer – a modern architecture based on attention mechanisms, which has revolutionized natural language processing (NLP) and is the foundation of models like BERT and GPT.
Example: Image classification using a simple CNN in Keras (Python)
python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
print(model.summary())Key Differences Between Machine Learning and Deep Learning
Although Deep Learning (DL) is a subfield of Machine Learning (ML), the two approaches differ in many ways. Understanding these differences helps you better choose the right technology for a specific problem and effectively leverage the capabilities of artificial intelligence.
Data Requirements
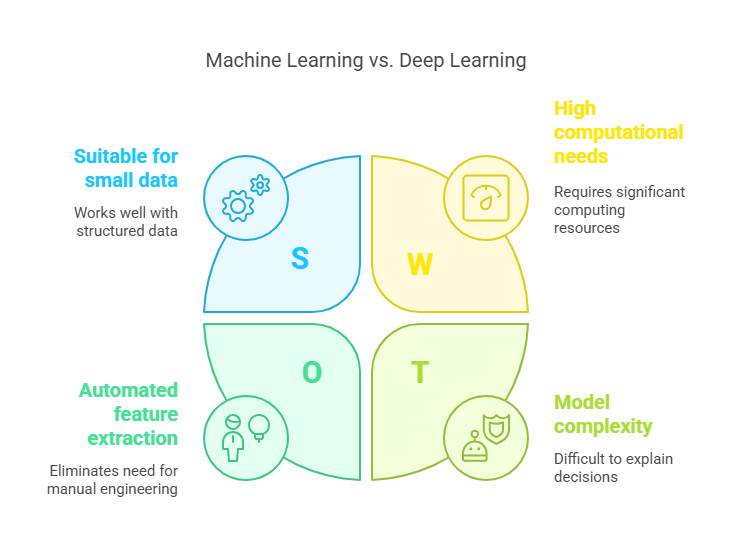
Machine Learning: Traditional ML algorithms, such as decision trees, regression, or SVM, work well with smaller, structured datasets. They often require manual preparation and feature engineering, i.e., selecting and transforming the most important information from the input data.
Deep Learning: DL models require very large datasets to achieve high accuracy. Thanks to deep neural networks, they can automatically extract features from raw data (e.g., images, text), eliminating the need for manual feature engineering.
Computational Needs
Machine Learning: ML algorithms are generally less demanding in terms of computational power and can be run on standard computers.
Deep Learning: Training deep neural networks requires significant computational resources, such as graphics processing units (GPUs) or TPUs. High hardware requirements translate into longer training times and higher costs.
Model Complexity and Interpretability
Machine Learning: ML models, especially simple ones (e.g., linear regression, decision trees), are easy to interpret. You can understand which features influence the model’s decisions, which is important in regulated sectors (e.g., finance, healthcare).
Deep Learning: DL models are complex and operate as “black boxes”—it is difficult to explain why they made a particular decision. Interpretability is one of the main challenges in deep learning.
Training and Deployment Time
Machine Learning: ML models train quickly and can be deployed almost immediately after data preparation.
Deep Learning: Training DL models is time-consuming, especially with large datasets and complex architectures. Deployment often requires additional optimization and testing.
Examples of Machine Learning Applications
Machine learning is widely used across many industries and everyday technologies. Thanks to the diversity of algorithms and relatively low hardware requirements, Machine Learning is utilized by large corporations as well as smaller companies and research institutions.
Data Analysis and Prediction
One of the most popular applications of ML is analyzing historical data and predicting future events. Examples include sales forecasting, predicting product demand, market trend analysis, or credit risk assessment. Regression models and decision trees enable quick and effective forecasting based on available data.
Example: Sales forecasting using linear regression (Python)
python
import numpy as np
from sklearn.linear_model import LinearRegression
# Sample data: number of months and sales
months = np.array([1, 2, 3, 4, 5, 6]).reshape(-1, 1)
sales = np.array([100, 120, 130, 150, 170, 180])
# Train the linear regression model
model = LinearRegression()
model.fit(months, sales)
# Forecast for the next month
next_month = np.array([[7]])
predicted_sales = model.predict(next_month)
print(f"Forecasted sales in month 7: {predicted_sales[0]:.0f}")Recommendation Systems
Machine Learning is the foundation of recommendation systems that suggest products, movies, music, or articles to users based on their previous choices and preferences. Algorithms such as k-nearest neighbors (KNN) or matrix factorization analyze user behavior and help personalize the offer.
Fraud Detection
ML is widely used in the financial sector for detecting fraud and anomalies in transactions. Classification models analyze behavioral patterns and flag unusual operations that may indicate attempted fraud or abuse. This enables banks and payment companies to respond to threats more quickly and minimize losses.
Examples of Deep Learning Applications
Deep Learning has revolutionized many fields, enabling the solution of problems that were beyond the reach of classical machine learning algorithms. Thanks to deep neural networks, it has become possible to automatically analyze images, audio, and text on an unprecedented scale.
Image and Audio Recognition
One of the most important applications of Deep Learning is image and audio recognition. Convolutional neural networks (CNNs) can automatically detect objects in photos, classify images, and even generate new graphics. In the field of audio, neural networks are used for speech recognition, speaker identification, and emotion analysis in recordings.
Example: Image classification using Keras (Python)
python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
print(model.summary())
Natural Language Processing (NLP)Deep Learning is the foundation of modern natural language processing systems. Models such as Transformer, BERT, and GPT enable automatic translation, text generation, sentiment analysis, question answering, and document summarization. Thanks to attention mechanisms, these networks can analyze context and dependencies in long texts.
Autonomous Vehicles and Robotics
Deep Learning plays a key role in the development of autonomous vehicles and robotics. Neural networks analyze data from cameras, radars, and sensors, recognize road signs, pedestrians, obstacles, and make real-time decisions. This enables safe autonomous driving, automatic parking, and robot navigation in complex environments.
When to Choose Machine Learning and When to Choose Deep Learning?
The choice between Machine Learning (ML) and Deep Learning (DL) depends on many factors, such as the type of problem, data availability, interpretability requirements, and technical resources. Making the right decision allows you to optimize project efficiency and achieve the best results.
Criteria for Choosing the Technology
Size and Type of Data:
If you have a limited amount of data or it is well-structured (e.g., tables, numbers), classical ML algorithms will be more effective and easier to implement. Deep Learning requires large, often unstructured datasets, such as images, text, or audio.
Problem Complexity:
ML is suitable for simpler tasks such as classification, regression, or customer segmentation. DL is a better choice for complex problems where automatic feature extraction is key, such as image recognition, natural language processing, or signal analysis.
Interpretability Requirements:
If it is important to understand how the model makes decisions (e.g., in finance or medicine), it is better to choose ML, where models are more transparent. DL acts as a “black box” and its decisions are harder to explain.
Computational Resources and Time:
ML requires less computational power and trains faster. DL needs powerful graphics processors (GPU/TPU) and longer training times.
Example Decision Scenarios
Machine Learning:
Analysis of tabular data (e.g., credit scoring, sales forecasting)
Customer segmentation based on demographic features
Anomaly detection in numerical data
Deep Learning:
Face recognition in photos
Automatic text translation
Audio analysis and speech recognition
Text or image generation
Challenges and Limitations of Both Approaches
Both Machine Learning and Deep Learning have their limitations and face specific challenges when implemented in practice. Understanding these barriers allows you to better prepare for AI projects and minimize the risk of failure.
Overfitting
Overfitting is a situation where a model learns the training data too precisely, losing its ability to generalize to new, unseen data. This is a particularly common problem in Deep Learning, where complex neural networks can memorize even random noise in the data. In ML, overfitting mainly occurs with overly complex models or too little data.
How to deal with it?
Using techniques such as cross-validation, regularization, early stopping, or data augmentation helps reduce the risk of overfitting.
Model Interpretability
Machine Learning models, especially simple ones (e.g., linear regression, decision trees), are relatively easy to interpret. You can understand which features influence the model’s decisions. In Deep Learning, interpretability is much more difficult—neural networks act as “black boxes,” making it hard to explain why the model made a particular decision. This challenge is especially important in regulated industries such as medicine or finance.
Costs
Deep Learning requires significant computational resources (GPU/TPU), which means higher hardware, energy, and training time costs. Machine Learning is more economical in this regard, especially with smaller datasets and simpler problems.
Data Availability and Quality
Both approaches are sensitive to the quality and quantity of data. Deep Learning needs huge, well-labeled datasets, while ML requires well-prepared and cleaned data. Gaps, errors, or inconsistencies in the data can lead to incorrect predictions and low model effectiveness.
The Future of Machine Learning and Deep Learning
Both Machine Learning (ML) and Deep Learning (DL) are developing dynamically, and their future looks extremely promising. New algorithms, architectures, and learning techniques are opening the door to solving increasingly complex problems and creating intelligent systems that are changing the way we live and work.
New Trends and Directions of Development
Explainable AI (XAI):
There is a growing emphasis on the interpretability of AI models. Techniques are being developed that allow us to understand why a model made a particular decision, which is crucial in regulated sectors and situations where trust in AI is essential.
Federated Learning:
Federated learning enables models to be trained on decentralized data without the need to collect it in one place. This is especially important in the context of privacy protection and data security.
AutoML:
Automation of the process of creating ML and DL models, from algorithm selection, through hyperparameter optimization, to deployment. AutoML shortens the time and reduces the costs of building AI systems.
Transfer Learning:
Using knowledge gained from training a model on one task to improve performance on another, related task. Transfer Learning saves time and resources, especially when data is limited.
Generative AI:
Generative models, such as GANs (Generative Adversarial Networks) or transformer models, can generate new data such as images, texts, music, or video. They have wide applications in creative industries and content automation.

Additional Resources
Links to Articles, Courses, and Libraries
To deepen your knowledge of Machine Learning and Deep Learning, it’s worth using reputable sources that offer both theoretical foundations and practical examples, as well as tools for self-study and experimentation. Here are some recommended resources:
Articles and Reports:
Google AI Blog – news and updates from the world of AI and ML
DeepMind Blog – research and innovations in Deep Learning
Towards Data Science – practical articles, tutorials, and analyses
Online Courses:
Coursera: Machine Learning (Andrew Ng) – one of the most popular introductory courses to ML
Deep Learning Specialization (Andrew Ng, Coursera) – a comprehensive course on deep learning
Fast.ai: Practical Deep Learning for Coders – a practical approach to deep learning
Tools and Libraries:
scikit-learn – a popular ML library in Python
TensorFlow – a framework for building and training deep learning models
PyTorch – a flexible and intuitive deep learning library
Keras – a high-level API for building neural networks
AI Agents in Industry: Revolutionizing Manufacturing and Logistics

