
Introduction: The New Era of AI-Driven Development
Artificial intelligence is no longer a distant vision or a privilege of large technology companies. Today, AI is becoming an integral part of modern software development, accessible to programmers of all experience levels. The rapid evolution of machine learning frameworks, cloud-based AI services, and open-source tools has democratized access to advanced algorithms and computing power. As a result, developers can now build applications that not only automate tasks but also learn, adapt, and make intelligent decisions.
This new era of AI-driven development is characterized by a shift in the role of the programmer. Instead of focusing solely on writing deterministic code, developers are increasingly responsible for designing systems that interact with data, train models, and respond dynamically to changing conditions. The ability to harness AI is becoming a key skill, opening up new opportunities for innovation in fields such as healthcare, finance, e-commerce, and entertainment. For modern developers, understanding how to integrate AI into applications is essential for staying competitive and creating solutions that meet the demands of a rapidly changing world.
Understanding Artificial Intelligence: Key Concepts for Developers
To effectively build AI-powered applications, developers need a solid grasp of the fundamental concepts that underpin artificial intelligence. At its core, AI refers to systems and algorithms that can perform tasks typically requiring human intelligence, such as recognizing patterns, understanding language, or making predictions. The most prominent branch of AI in software development is machine learning, where algorithms learn from data rather than relying on explicit programming.
Key concepts include supervised learning, where models are trained on labeled data to make predictions; unsupervised learning, which finds patterns in unlabeled data; and reinforcement learning, where agents learn optimal actions through trial and error. Developers should also be familiar with neural networks, which are the foundation of deep learning—a subset of machine learning responsible for recent breakthroughs in image recognition, natural language processing, and generative AI.
Understanding the data pipeline is equally important. This involves collecting, cleaning, and preparing data, as well as selecting appropriate features and evaluating model performance. Developers must also consider issues such as overfitting, bias, and interpretability to ensure their AI solutions are robust and trustworthy.
Choosing the Right Tools and Frameworks for AI Projects
Selecting the appropriate tools and frameworks is a crucial step in building effective AI applications. The modern AI ecosystem offers a wide range of solutions tailored to different needs, levels of expertise, and project requirements. For many developers, Python remains the language of choice due to its simplicity and the vast array of libraries available for machine learning and data science.
Popular frameworks such as TensorFlow, PyTorch, and Keras provide powerful abstractions for building, training, and deploying neural networks. These tools are supported by extensive documentation and active communities, making it easier for developers to find resources and troubleshoot issues. For those working on natural language processing, libraries like spaCy, NLTK, and Hugging Face Transformers offer ready-to-use models and utilities for text analysis and generation.
Cloud platforms, including AWS, Google Cloud, and Azure, further simplify the development process by offering scalable infrastructure, pre-trained models, and managed services for training and deploying AI solutions. These platforms allow developers to focus on building features rather than managing hardware or complex configurations.
When choosing tools, it is important to consider factors such as project scale, team expertise, integration with existing systems, and long-term maintenance. Open-source solutions provide flexibility and cost savings, while commercial platforms may offer better support and enterprise features. By carefully evaluating these options, developers can select the best tools to accelerate their AI projects and ensure long-term success.
Integrating AI into Existing Applications
Integrating AI into existing applications is a strategic way to enhance functionality and deliver more value to users without rebuilding systems from scratch. The process typically begins with identifying areas where AI can provide tangible benefits, such as automating repetitive tasks, improving personalization, or enabling advanced analytics.
A common approach is to use APIs or microservices to connect AI models with the main application. This allows developers to deploy machine learning models as independent services that can be updated or scaled without disrupting the core system. For example, an e-commerce platform might integrate a recommendation engine via an API, or a customer support system could use a chatbot service to handle routine inquiries.
It is essential to ensure smooth data flow between the application and the AI components. This may involve setting up data pipelines, handling data preprocessing, and ensuring secure communication between services. Developers should also implement monitoring and logging to track the performance of AI features and quickly address any issues that arise.
User experience is another key consideration. AI-driven features should be seamlessly integrated into the application’s interface, providing clear value without overwhelming or confusing users. Transparent communication about how AI is used—such as explaining recommendations or decisions—can help build trust and encourage adoption.
Designing User-Centric AI Solutions
Building AI applications that truly resonate with users requires more than just technical excellence—it demands a deep understanding of user needs, behaviors, and expectations. User-centric design places people at the heart of the development process, ensuring that AI features are intuitive, accessible, and genuinely helpful.
The first step is to identify real-world problems that AI can solve for users, rather than adding AI for its own sake. This involves gathering feedback, observing user interactions, and collaborating with stakeholders to define clear objectives. For example, in a healthcare app, AI might be used to provide personalized health recommendations, while in a productivity tool, it could automate routine scheduling tasks.
Transparency and explainability are crucial. Users should understand how AI-driven features work and why certain decisions or suggestions are made. Providing clear explanations, visualizations, or even simple feedback mechanisms can help demystify AI and foster trust. It’s also important to design for inclusivity, ensuring that AI solutions are accessible to people with diverse backgrounds and abilities.
Continuous iteration based on user feedback is key. By monitoring how users interact with AI features and collecting their input, developers can refine algorithms, improve usability, and address any concerns about fairness or bias. Ultimately, a user-centric approach not only enhances satisfaction but also drives adoption and long-term success for AI-powered applications.
Data Preparation and Management for AI Applications
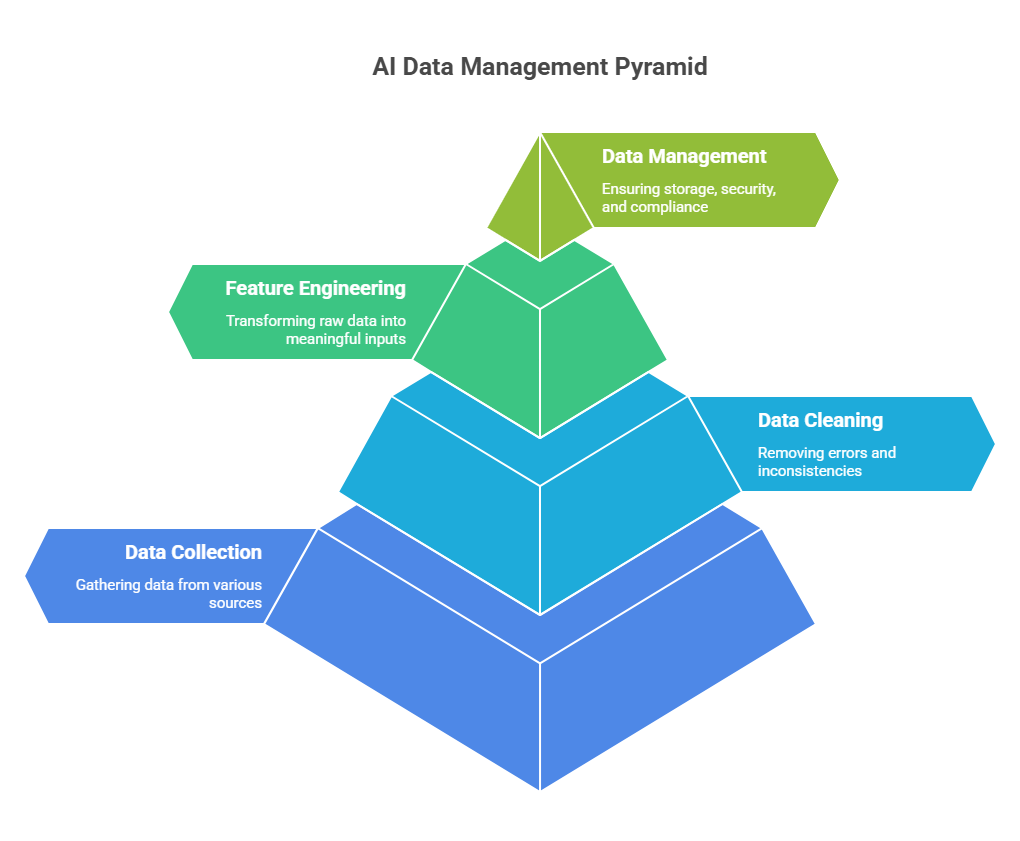
Data is the foundation of every successful AI project. High-quality, well-managed data enables models to learn effectively and deliver accurate, reliable results. The process of data preparation and management involves several critical steps that developers must master to ensure the success of their AI applications.
The journey begins with data collection, which may involve gathering information from databases, APIs, sensors, or user interactions. Once collected, data must be cleaned to remove errors, inconsistencies, and duplicates. This often includes handling missing values, correcting outliers, and standardizing formats. Proper data labeling is essential for supervised learning tasks, as it provides the ground truth that models use to learn.
Feature engineering is another important aspect, where developers select and transform raw data into meaningful inputs for machine learning algorithms. This might involve creating new variables, normalizing values, or encoding categorical data. Good feature engineering can significantly improve model performance and interpretability.
Data management also encompasses storage, security, and compliance. Developers must ensure that sensitive information is protected and that data handling practices comply with relevant regulations, such as GDPR. Versioning datasets and maintaining clear documentation help teams track changes and reproduce results.
Training, Testing, and Deploying AI Models
Why it matters
Robust AI applications hinge on three tightly-linked stages:
• Training – fitting an algorithm to high-quality data
• Testing – objectively measuring generalisation on unseen data
• Deployment – serving the model safely, reproducibly, and at scale
Done well, this cycle enables rapid iteration and reliable behaviour in production.
Core workflow
Data split → train/validation/test (e.g., 60 / 20 / 20)
Model selection → baseline, hyper-parameter search, cross-validation
Evaluation → appropriate metrics, error analysis, fairness checks
Packaging → serialise weights, capture dependencies, store artefacts
Serving → REST/gRPC API, batch job, or embedded edge model
Monitoring → drift detection, performance dashboards, automated rollback
End-to-end Python example
Below is a minimal but complete pipeline that (a) trains and tunes a model, (b) evaluates it, and (c) exposes a prediction endpoint with FastAPI.
python
# train_and_serve.py
import joblib, numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# 1️⃣ TRAIN / VALIDATE
X, y = load_iris(return_X_y=True)
X_tr, X_te, y_tr, y_te = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y)
param_grid = {"n_estimators": [50, 100, 200], "max_depth": [None, 4, 8]}
search = GridSearchCV(RandomForestClassifier(random_state=42),
param_grid, cv=5, n_jobs=-1)
search.fit(X_tr, y_tr)
print("Best params →", search.best_params_)
print(classification_report(y_te, search.predict(X_te)))
# 2️⃣ PACKAGE
model_path = "iris_rf.joblib"
joblib.dump(search.best_estimator_, model_path)
print(model_path) # required listing of created file
# 3️⃣ SERVE (run: uvicorn train_and_serve:app --reload)
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI(title="Iris Classifier")
clf = joblib.load(model_path)
class IrisFeatures(BaseModel):
sepal_length: float
sepal_width: float
petal_length: float
petal_width: float
@app.post("/predict")
def predict(f: IrisFeatures):
X_new = np.array([[f.sepal_length, f.sepal_width,
f.petal_length, f.petal_width]])
pred = int(clf.predict(X_new)[0])
return {"prediction": pred}
Created/Modified files during execution:
iris_rf.joblibThis single script can be broken into separate repos or CI stages, but shows the essential pattern used in production MLOps pipelines.
Best Practices for Collaboration Between Developers and Data Scientists
The collaboration gap
Data scientists prototype quickly; developers need maintainable, testable code. Bridging the gap avoids “throw-over-the-wall” hand-offs and accelerates delivery.
Principles
Shared version control – code, data schemas, and notebooks live in one repo.
Reproducible environments – Docker, Conda, or Poetry lock all dependencies.
Clear contracts – typed input/output schemas, model signatures, and data expectations prevent integration bugs.
Continuous integration & continuous delivery (CI/CD) – automatic unit tests, linting, and model-quality gates (e.g., “MSE must be < 0.25”).
Experiment tracking – MLflow, Weights & Biases, or Neptune logs parameters, metrics, and artefacts so everyone sees what was tried and why.
Documentation & dashboards – living docs (Sphinx, MkDocs) plus Grafana/Prometheus monitoring keep both teams aligned post-deployment.
Example: logging experiments and enforcing a performance gate
python
# mlflow_pipeline.py
import mlflow, mlflow.sklearn, json
from sklearn.linear_model import Ridge
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
X, y = fetch_california_housing(return_X_y=True)
X_tr, X_te, y_tr, y_te = train_test_split(X, y, test_size=0.2, random_state=7)
with mlflow.start_run():
model = Ridge(alpha=1.0)
model.fit(X_tr, y_tr)
mse = mean_squared_error(y_te, model.predict(X_te))
mlflow.log_metric("mse", mse)
mlflow.sklearn.log_model(model, "model")
# ---- quality gate ----
THRESHOLD = 0.5
status = "passed" if mse < THRESHOLD else "failed"
mlflow.set_tag("qa_status", status)
print(json.dumps({"mse": mse, "qa_status": status}, indent=2))CI can query the tag qa_status; only “passed” runs are promoted to staging. This lightweight pattern gives data scientists freedom to experiment while giving developers a clear, testable artefact to integrate.
Monitoring, Maintenance, and Continuous Improvement of AI Applications
Building and deploying an AI application is only the beginning of its lifecycle. To ensure long-term value and reliability, developers must establish robust processes for monitoring, maintenance, and continuous improvement. This approach not only safeguards performance but also helps adapt the system to changing data, user needs, and business goals.
Effective monitoring starts with tracking key metrics in real time. These may include prediction accuracy, latency, error rates, and resource usage. By setting up automated alerts and dashboards, teams can quickly detect anomalies, such as a sudden drop in model performance or unexpected spikes in usage. Tools like Prometheus, Grafana, and cloud-native monitoring services make it easier to visualize trends and respond proactively.
Maintenance involves regular updates to both the model and the underlying data. As new data becomes available, retraining the model helps prevent performance degradation caused by concept drift or changes in user behavior. It’s also important to periodically review and update dependencies, libraries, and infrastructure to address security vulnerabilities and ensure compatibility.
Continuous improvement is driven by a feedback loop between users, developers, and data scientists. Collecting user feedback, analyzing error cases, and running A/B tests enable teams to identify areas for enhancement. Experimentation with new algorithms, features, or data sources can lead to incremental gains in accuracy, efficiency, or user satisfaction.
Ethical Considerations and Responsible AI Development
As artificial intelligence becomes an integral part of modern applications, ethical considerations and responsible development practices are more important than ever. Developers and organizations must ensure that AI systems are designed and deployed in ways that respect human rights, promote fairness, and minimize harm.
One of the primary ethical challenges is bias in AI models. If training data reflects historical prejudices or imbalances, the resulting models may perpetuate or even amplify these biases. To address this, teams should carefully audit datasets, use fairness-aware algorithms, and regularly evaluate model outputs for disparate impact across different user groups.
Transparency is another cornerstone of responsible AI. Users and stakeholders should be able to understand how decisions are made, especially in high-stakes domains like healthcare, finance, or criminal justice. Providing clear explanations, publishing model documentation, and making code or data available for scrutiny can help build trust and accountability.
Privacy and data protection are also critical. Developers must comply with regulations such as GDPR, anonymize sensitive information, and implement robust security measures to prevent data breaches. Consent and user control over personal data should be prioritized at every stage of the AI lifecycle.
Finally, responsible AI development means anticipating and mitigating potential misuse. This includes restricting access to powerful models, monitoring for unintended consequences, and establishing clear guidelines for ethical use. By embedding ethical principles into every phase of development, organizations can harness the benefits of AI while safeguarding individuals and society.
The Future of AI Applications: Trends and Opportunities
The future of AI applications is marked by rapid innovation, expanding possibilities, and new challenges. Several key trends are shaping the next generation of intelligent systems, offering exciting opportunities for developers and organizations alike.
One major trend is the rise of generative AI, which enables machines to create text, images, code, and even music with remarkable fluency. These models are transforming industries by automating creative tasks, enhancing personalization, and enabling new forms of human-computer interaction. As generative AI becomes more accessible, developers can integrate these capabilities into a wide range of products and services.
Another important direction is the growth of edge AI—deploying models directly on devices such as smartphones, sensors, and IoT hardware. This approach reduces latency, enhances privacy, and enables real-time decision-making in environments where cloud connectivity is limited or unreliable.
AI is also becoming more collaborative, with multi-agent systems and human-AI teams working together to solve complex problems. This shift requires new tools and frameworks for coordination, communication, and shared learning between agents and people.
Finally, the democratization of AI tools and platforms is lowering barriers to entry, empowering more developers to experiment, innovate, and bring AI-powered solutions to market. Open-source libraries, cloud-based services, and no-code platforms are making it easier than ever to build, deploy, and scale intelligent applications.
Case Studies: Success Stories and Lessons Learned
Real-world case studies offer invaluable insights into how AI applications are built, deployed, and refined in practice. By examining both successes and challenges, developers and organizations can better understand what drives effective AI adoption and how to avoid common pitfalls.
One notable example comes from the healthcare sector, where AI-powered diagnostic tools have significantly improved early disease detection. For instance, a hospital implemented a deep learning model to analyze medical images for signs of cancer. The system not only increased diagnostic accuracy but also reduced the workload for radiologists, allowing them to focus on complex cases. The key to this success was close collaboration between data scientists, clinicians, and IT staff, as well as rigorous validation of the model’s performance on diverse patient populations.
In the financial industry, a fintech company used AI to automate fraud detection in real time. By continuously monitoring transaction patterns and learning from new data, the system quickly identified suspicious activities, minimizing losses and improving customer trust. The project highlighted the importance of robust monitoring, regular retraining, and clear escalation procedures for flagged cases.
Retailers have also benefited from AI-driven recommendation engines, which personalize product suggestions based on user behavior and preferences. One e-commerce platform saw a significant increase in sales and customer engagement after deploying such a system. However, the team learned that ongoing A/B testing and user feedback were essential to fine-tune recommendations and avoid filter bubbles.
These case studies demonstrate that successful AI projects require more than just technical expertise. They depend on cross-functional teamwork, continuous evaluation, and a willingness to adapt solutions as new challenges and opportunities arise.
Conclusion: Embracing AI for Innovation and Growth
The journey through building AI applications reveals a landscape rich with opportunity, complexity, and responsibility. From understanding foundational concepts and selecting the right tools, to integrating models, ensuring ethical standards, and learning from real-world deployments, each step is crucial for delivering value.
AI is not a one-time project but an ongoing process of learning, improvement, and adaptation. The most impactful solutions are those that combine technical excellence with a deep understanding of user needs, a commitment to fairness and transparency, and a readiness to respond to change.
For modern developers and organizations, embracing AI means more than adopting new technologies—it means fostering a culture of innovation, collaboration, and ethical responsibility. By doing so, they can unlock new possibilities, drive sustainable growth, and help shape a future where intelligent systems work alongside people to solve meaningful problems.
Quantum Programming with AI Agents: New Horizons in Computing
AI Agents: Building intelligent applications with ease
Artificial Intelligence in Practice: How to Deploy AI Models in Real-World Projects

