
Introduction to AI Agent Lifecycle Management: From Deployment to Self-Healing and Online Updates
Managing the lifecycle of AI agents is a critical challenge for experienced programmers building robust, production-ready intelligent systems. As AI agents become more autonomous and are deployed at scale, understanding their lifecycle—from initial deployment to self-healing and continuous online updates—becomes essential for ensuring reliability, adaptability, and business value. In this article, we introduce the concept of AI agent lifecycle management, explain why it matters, and provide an overview of the key stages involved.
1.1 What Are AI Agents?
AI agents are autonomous software entities capable of perceiving their environment, making decisions, and taking actions to achieve specific goals. Unlike traditional software, AI agents often leverage machine learning, reinforcement learning, or other advanced techniques to adapt their behavior over time. They can operate in dynamic, unpredictable environments, making them suitable for applications such as robotics, process automation, recommendation systems, and intelligent assistants.
1.2 Why Lifecycle Management Matters
The lifecycle of an AI agent encompasses all phases from initial design and deployment to ongoing maintenance, adaptation, and eventual retirement. Effective lifecycle management is crucial for several reasons. First, it ensures that agents remain reliable and performant as their operating environment changes. Second, it enables rapid detection and correction of failures or degradations, minimizing downtime and business risk. Third, it supports compliance, governance, and traceability—key requirements in regulated industries. Finally, lifecycle management allows for continuous improvement, enabling agents to learn from new data and adapt to evolving requirements.
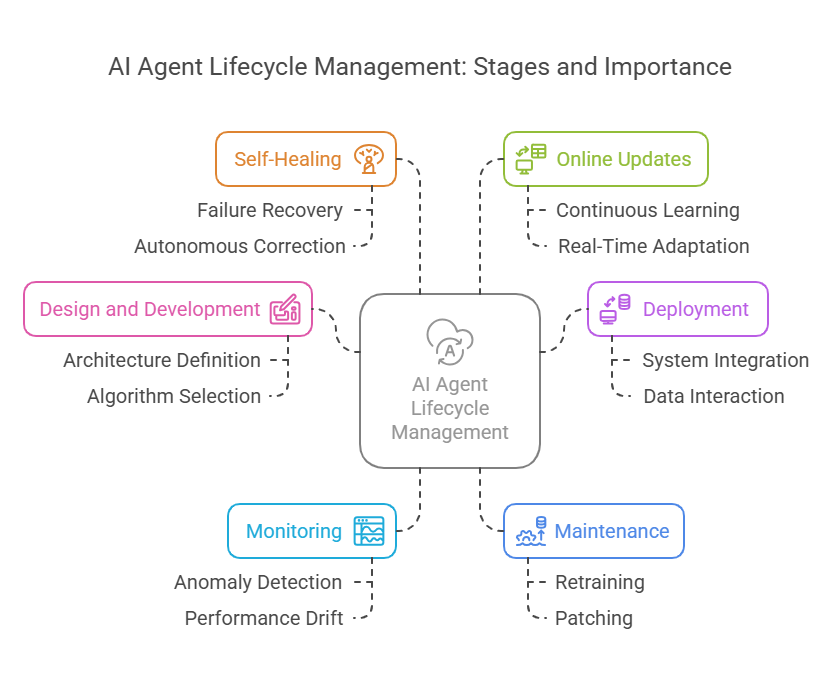
1.3 Key Stages of the AI Agent Lifecycle
The lifecycle of an AI agent typically includes several interconnected stages. It begins with design and development, where the agent’s architecture, learning algorithms, and interfaces are defined. Next comes deployment, where the agent is integrated into production systems and begins interacting with real-world data. Once deployed, agents require ongoing monitoring to detect anomalies, performance drift, or security threats. Maintenance activities, such as retraining, patching, and updating, are essential to keep agents effective and secure. Advanced agents may also feature self-healing capabilities, allowing them to autonomously recover from certain types of failures. Finally, online updates and continuous learning enable agents to adapt in real time, ensuring long-term relevance and value.
Practical Example: Monitoring an AI Agent in Python
To illustrate the importance of lifecycle management, consider a simple example of monitoring an AI agent’s performance using Python. Suppose you have a reinforcement learning agent deployed in production. You want to track its reward over time and detect when its performance drops below a critical threshold.
python
import numpy as np
import matplotlib.pyplot as plt
# Simulated rewards over 100 episodes
rewards = np.random.normal(loc=100, scale=10, size=100)
rewards[50:60] -= 40 # Simulate a performance drop
# Detect performance drop
threshold = 70
anomalies = np.where(rewards < threshold)[0]
plt.plot(rewards, label='Episode Reward')
plt.axhline(y=threshold, color='r', linestyle='--', label='Threshold')
plt.scatter(anomalies, rewards[anomalies], color='red', label='Anomaly')
plt.xlabel('Episode')
plt.ylabel('Reward')
plt.title('AI Agent Performance Monitoring')
plt.legend()
plt.show()This code simulates an agent’s reward signal, introduces a performance drop, and visualizes anomalies. In a real-world system, such monitoring would trigger alerts or initiate self-healing routines, such as rolling back to a previous model version or retraining the agent.
Designing and Developing AI Agents
The design and development phase is the foundation of the AI agent lifecycle. For experienced programmers, this stage is where architectural decisions, technology selection, and robust implementation practices set the stage for successful deployment and long-term maintainability. Below, we break down the key subpoints of this phase.
2.1 Choosing Architecture and Technology
Selecting the right architecture and technology stack is crucial for building scalable, maintainable, and efficient AI agents. Programmers must consider whether the agent will be rule-based, use machine learning, or leverage reinforcement learning. The choice of frameworks (such as TensorFlow, PyTorch, or scikit-learn), programming languages (Python is the most popular due to its extensive AI ecosystem), and supporting tools (like Docker for containerization or Kubernetes for orchestration) will impact the agent’s flexibility and performance. Additionally, the architecture should support modularity, allowing for easy updates and integration with other systems.
2.2 Programming and Training AI Agents
Once the architecture is defined, the next step is to implement the agent’s logic and train its models. This involves writing clean, well-documented code, following best practices such as version control (using Git), and adhering to coding standards (like PEP 8 for Python). For machine learning agents, this phase includes data preprocessing, feature engineering, model selection, and training. Reinforcement learning agents require the definition of environments, reward functions, and training loops. It is essential to use reproducible workflows, leveraging tools like Jupyter notebooks or experiment tracking platforms (e.g., MLflow).
Here is a simple Python example of training a reinforcement learning agent using the popular stable-baselines3 library:
python
import gym
from stable_baselines3 import PPO
# Create environment
env = gym.make("CartPole-v1")
# Initialize agent
model = PPO("MlpPolicy", env, verbose=1)
# Train agent
model.learn(total_timesteps=10000)
# Save the trained model
model.save("ppo_cartpole_agent")
Created/Modified files during execution:
print("ppo_cartpole_agent.zip")This code demonstrates the core steps: environment creation, agent initialization, training, and saving the model for later deployment.
#### 2.3 Testing and Validating AI Models
Testing and validation are critical to ensure that AI agents behave as expected and generalize well to new data. This process includes unit testing of code, integration testing with other system components, and rigorous evaluation of model performance using validation datasets. For machine learning models, common metrics include accuracy, precision, recall, and F1-score. For reinforcement learning agents, average reward and episode length are typical metrics. Cross-validation and A/B testing can further validate the agent’s robustness.
Automated testing frameworks (such as `pytest` for Python) and continuous integration tools (like GitHub Actions or Jenkins) help maintain code quality and catch issues early. Below is a simple example of a unit test for an agent’s action selection method:
python
import pytest
def test_agent_action(agent, env):
obs = env.reset()
action, _ = agent.predict(obs)
assert env.action_space.contains(action)By thoroughly testing and validating AI agents before deployment, programmers can minimize the risk of failures in production and ensure that the agents deliver reliable, high-quality results.
Deploying AI Agents
Deploying AI agents is a pivotal stage in the agent lifecycle, transforming a well-designed and thoroughly tested agent into a production-ready system that delivers real value. For experienced programmers, this phase involves more than just moving code to a server—it requires careful planning, automation, and integration to ensure reliability, scalability, and maintainability. Below, we explore the key aspects of deploying AI agents, from preparing the production environment to automating deployments and integrating with existing systems.
3.1 Preparing the Production Environment
Before deployment, it is essential to prepare a robust production environment tailored to the needs of AI agents. This includes selecting the right hardware (CPUs, GPUs, or TPUs), configuring operating systems, and setting up necessary dependencies and libraries. Containerization tools like Docker are widely used to encapsulate the agent and its environment, ensuring consistency across development, testing, and production. Orchestration platforms such as Kubernetes can manage multiple agent instances, handle scaling, and provide fault tolerance. Security considerations—such as network segmentation, access controls, and secrets management—are also critical at this stage to protect both the agent and the data it processes.
3.2 Automating Deployments (CI/CD for AI Agents)
Automation is key to efficient and reliable deployment of AI agents. Continuous Integration and Continuous Deployment (CI/CD) pipelines streamline the process of building, testing, and releasing new agent versions. Tools like GitHub Actions, GitLab CI, Jenkins, or cloud-native solutions (e.g., AWS CodePipeline, Azure DevOps) can automate the entire workflow. A typical CI/CD pipeline for AI agents includes steps such as code linting, unit and integration testing, building Docker images, and deploying to staging or production environments. Automated rollbacks and canary deployments help minimize risk by allowing new versions to be tested on a subset of users before full rollout.
Here is a simplified example of a GitHub Actions workflow for deploying a Python-based AI agent using Docker:
yaml
name: Deploy AI Agent
on:
push:
branches: [ "main" ]
jobs:
build-and-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Build Docker image
run: docker build -t my-ai-agent:latest .
- name: Push Docker image
run: |
echo ${{ secrets.DOCKER_PASSWORD }} | docker login -u ${{ secrets.DOCKER_USERNAME }} --password-stdin
docker tag my-ai-agent:latest myrepo/my-ai-agent:latest
docker push myrepo/my-ai-agent:latest
- name: Deploy to Kubernetes
run: kubectl apply -f k8s/deployment.yaml
Created/Modified files during execution:
print(".github/workflows/deploy-ai-agent.yml")This workflow checks out the code, sets up Python, installs dependencies, builds and pushes a Docker image, and deploys the agent to a Kubernetes cluster.
#### 3.3 Integration with Existing Systems
AI agents rarely operate in isolation. Successful deployment requires seamless integration with existing systems, such as databases, APIs, message queues, and monitoring tools. This often involves implementing RESTful APIs or gRPC endpoints for communication, configuring secure data pipelines, and ensuring compatibility with enterprise authentication and authorization mechanisms. Logging and monitoring should be integrated from the start, using tools like Prometheus, Grafana, or ELK Stack to track agent health, performance, and errors in real time.
For example, integrating an AI agent with a REST API in Python can be achieved using frameworks like FastAPI:
python
from fastapi import FastAPI, Request
app = FastAPI()
@app.post("/predict")
async def predict(request: Request):
data = await request.json()
# Process input and generate prediction
result = my_agent.predict(data)
return {"prediction": result}This code snippet exposes a /predict endpoint, allowing other systems to interact with the deployed agent.
Monitoring and Maintaining AI Agents
Once AI agents are deployed, the work is far from over. Continuous monitoring and proactive maintenance are essential to ensure that agents remain reliable, performant, and secure in dynamic production environments. For experienced programmers, this phase involves setting up robust monitoring systems, detecting anomalies, collecting telemetry data, and implementing processes for rapid response to issues. Let’s explore the key aspects of monitoring and maintaining AI agents.
4.1 Monitoring Agent Performance and Behavior
Effective monitoring starts with tracking the right metrics. For AI agents, this typically includes performance indicators such as response time, resource utilization (CPU, GPU, memory), and task-specific metrics like accuracy, reward, or error rates. Monitoring frameworks such as Prometheus, Grafana, or cloud-native solutions (AWS CloudWatch, Azure Monitor) can be integrated to visualize and alert on these metrics in real time.
For example, in reinforcement learning agents, you might monitor the average reward per episode, the number of successful task completions, or the frequency of policy updates. In production, it’s also important to track system-level metrics to detect bottlenecks or failures early.
Here’s a simple Python example using the psutil library to monitor resource usage:
python
import psutil
import time
while True:
cpu = psutil.cpu_percent(interval=1)
mem = psutil.virtual_memory().percent
print(f"CPU: {cpu}%, Memory: {mem}%")
time.sleep(5)This script prints CPU and memory usage every five seconds, which can be extended to log data or trigger alerts.
4.2 Detecting Anomalies and Errors
Anomaly detection is crucial for identifying unexpected agent behaviors or system failures. This can involve setting static thresholds (e.g., if accuracy drops below 80%) or using statistical and machine learning methods to detect outliers in performance data. Automated alerting systems can notify engineers when anomalies are detected, enabling rapid investigation and mitigation.
For example, you might use a rolling window to compute the mean and standard deviation of a performance metric, flagging any value that deviates significantly from the norm:
python
import numpy as np
def detect_anomalies(data, window=10, threshold=2):
anomalies = []
for i in range(window, len(data)):
window_data = data[i-window:i]
mean = np.mean(window_data)
std = np.std(window_data)
if abs(data[i] - mean) > threshold * std:
anomalies.append(i)
return anomaliesThis function flags indices where the metric deviates more than two standard deviations from the rolling mean.
4.3 Collecting and Analyzing Telemetry Data
Telemetry data provides deep insights into agent behavior and system health. This includes logs, traces, and custom events generated by the agent during operation. Centralized log management solutions like the ELK Stack (Elasticsearch, Logstash, Kibana) or cloud-based logging services can aggregate and visualize this data for analysis.
Telemetry analysis helps identify trends, diagnose issues, and support root cause analysis. For example, by correlating spikes in error logs with drops in performance metrics, you can quickly pinpoint the source of a problem.
A practical approach is to instrument your agent code with structured logging:
python
import logging
logging.basicConfig(filename='agent.log', level=logging.INFO)
def agent_action(action):
logging.info(f"Action taken: {action}")
# ... agent logic ...This ensures that every significant event is recorded and can be reviewed later.
Self-Healing AI Agents
As AI agents become more autonomous and are deployed in increasingly complex environments, the ability to self-heal—detecting, diagnosing, and recovering from failures without human intervention—becomes a critical feature. Self-healing mechanisms not only improve system reliability and uptime but also reduce operational costs and the need for manual maintenance. In this section, we explore the core concepts and practical approaches to implementing self-healing in AI agents.
5.1 Failure and Degradation Detection Mechanisms
The first step in self-healing is the early detection of failures or performance degradation. This involves continuously monitoring the agent’s health and behavior using a combination of metrics, logs, and anomaly detection algorithms. Common signals include sudden drops in accuracy, increased error rates, resource exhaustion, or unexpected outputs.
For example, you can use statistical methods or machine learning models to detect anomalies in real-time data streams. Here’s a simple Python example using a rolling mean and standard deviation to flag anomalies in an agent’s performance metric:
python
import numpy as np
def detect_anomalies(data, window=20, threshold=2.5):
anomalies = []
for i in range(window, len(data)):
window_data = data[i-window:i]
mean = np.mean(window_data)
std = np.std(window_data)
if abs(data[i] - mean) > threshold * std:
anomalies.append(i)
return anomalies
# Example usage
performance = np.random.normal(100, 5, 100)
performance[60:65] -= 30 # Simulate a failure
anomalies = detect_anomalies(performance)
print("Anomalies detected at indices:", anomalies)
Created/Modified files during execution:
print("No files created; this is an in-memory example.")In production, these detection mechanisms can trigger alerts or initiate automated recovery routines.
#### 5.2 Automated Correction and Model Adaptation
Once a failure or degradation is detected, the agent must respond autonomously. Automated correction can take several forms, such as restarting a failed process, rolling back to a previous stable model version, or retraining the model with fresh data. More advanced agents may use online learning or reinforcement learning to adapt their behavior in real time.
A practical approach is to maintain a set of model checkpoints and implement logic to revert to the last known good state if a problem is detected. For example, in Python, you might load a backup model if the current one fails:
python
import joblib
def load_model(path):
try:
model = joblib.load(path)
print("Model loaded successfully.")
return model
except Exception as e:
print("Error loading model:", e)
# Fallback to backup
backup_path = path.replace(".pkl", "_backup.pkl")
model = joblib.load(backup_path)
print("Loaded backup model.")
return model
# Usage
model = load_model("agent_model.pkl")
Created/Modified files during execution:
print("No files created; this is an in-memory example.")This pattern ensures that the agent can recover from model corruption or deployment errors with minimal downtime.
#### 5.3 Examples of Self-Healing Implementation
Self-healing can be implemented at multiple levels, from infrastructure to application logic. For instance, container orchestration platforms like Kubernetes can automatically restart failed agent instances, while application-level scripts can monitor and repair model files or configurations.
A real-world example is an AI agent in a cloud environment that monitors its own API response times. If latency exceeds a threshold, the agent can trigger a self-healing workflow: scaling up resources, restarting services, or switching to a backup model. Here’s a simplified Python example that simulates this logic:
python
import time
import random
def monitor_and_heal():
for _ in range(10):
response_time = random.uniform(0.1, 1.5)
print(f"Response time: {response_time:.2f}s")
if response_time > 1.0:
print("High latency detected! Restarting service...")
# Simulate restart
time.sleep(1)
print("Service restarted.")
time.sleep(0.5)
monitor_and_heal()Online Updates and Continuous Learning for AI Agents
In the modern AI landscape, deploying an agent is only the beginning. To remain effective, AI agents must adapt to new data, changing environments, and evolving requirements. This is where online updates and continuous learning come into play. These capabilities allow agents to update their models in real time, leverage transfer learning, and manage versions and rollbacks efficiently. Below, we explore the key aspects of this stage in the AI agent lifecycle.
6.1 Methods for Real-Time Model Updates
Real-time model updates enable AI agents to incorporate new information and adapt their behavior without downtime. This is especially important in dynamic environments, such as financial trading, recommendation systems, or autonomous vehicles, where data patterns can shift rapidly.
There are several approaches to real-time updates. One common method is online learning, where the model is updated incrementally as new data arrives, rather than retraining from scratch. Algorithms like stochastic gradient descent (SGD) can be adapted for online learning, allowing the agent to refine its parameters continuously.
For example, using the partial_fit method in scikit-learn allows incremental updates to certain models:
python
from sklearn.linear_model import SGDClassifier
import numpy as np
# Simulate streaming data
X_stream = np.random.rand(100, 10)
y_stream = np.random.randint(0, 2, 100)
model = SGDClassifier()
for i in range(0, 100, 10):
X_batch = X_stream[i:i+10]
y_batch = y_stream[i:i+10]
model.partial_fit(X_batch, y_batch, classes=[0, 1])
Created/Modified files during execution:
print("No files created; this is an in-memory example.")This approach is efficient and well-suited for agents that need to learn from data streams.
#### 6.2 Transfer Learning and Adaptation to New Data
Transfer learning is a powerful technique that allows AI agents to leverage knowledge from previously learned tasks or domains. Instead of training a model from scratch, the agent starts with a pre-trained model and fine-tunes it on new data. This is especially useful when labeled data is scarce or when the agent must quickly adapt to a new environment.
For example, in computer vision, a convolutional neural network (CNN) pre-trained on ImageNet can be fine-tuned for a specific task with a smaller dataset. In reinforcement learning, agents can transfer policies learned in simulation to real-world environments, reducing the reality gap.
Here’s a simplified example using PyTorch to fine-tune a pre-trained model:
python
import torch
import torchvision.models as models
# Load a pre-trained ResNet model
model = models.resnet18(pretrained=True)
# Freeze all layers except the last
for param in model.parameters():
param.requires_grad = False
model.fc.requires_grad = True
# Replace the final layer for a new task
model.fc = torch.nn.Linear(model.fc.in_features, 2)
Created/Modified files during execution:
print("No files created; this is an in-memory example.")This enables rapid adaptation to new tasks with minimal training.
#### 6.3 Version Management and Rollback
As AI agents evolve, managing different versions of models becomes critical for reliability and compliance. Version management ensures that every model update is tracked, reproducible, and reversible if issues arise. This is especially important in regulated industries or mission-critical applications.
Best practices include using tools like MLflow, DVC, or custom versioning systems to track model artifacts, code, and data. Automated pipelines can deploy new versions, run validation tests, and roll back to previous versions if performance degrades.
A simple Python example for managing model versions might look like this:
python
import joblib
import os
def save_model(model, version):
filename = f"agent_model_v{version}.pkl"
joblib.dump(model, filename)
print(f"Model saved as {filename}")
def load_model(version):
filename = f"agent_model_v{version}.pkl"
if os.path.exists(filename):
return joblib.load(filename)
else:
raise FileNotFoundError(f"No model found for version {version}")
# Save and load model versions
# save_model(model, 1)
# model = load_model(1)
Created/Modified files during execution:
print("agent_model_v1.pkl") # Example filenameThis pattern can be extended with metadata, automated testing, and integration with CI/CD pipelines for robust version control.
Security and Resilience of AI Agents
As AI agents become more deeply integrated into business-critical systems, their security and resilience are paramount. Threats such as adversarial attacks, data manipulation, and system vulnerabilities can compromise not only the performance but also the trustworthiness of AI-driven solutions. For experienced programmers, building robust, secure, and resilient AI agents requires a multi-layered approach—combining technical safeguards, monitoring, and best practices throughout the agent lifecycle. Below, we explore the key aspects of securing and hardening AI agents.
7.1 Protection Against Attacks and Manipulation
AI agents are susceptible to a range of attacks, including adversarial examples, data poisoning, model inversion, and evasion attacks. Adversarial attacks involve crafting subtle input perturbations that cause the agent to make incorrect decisions, while data poisoning targets the training data to corrupt the model’s behavior.
To defend against these threats, several strategies can be employed. Adversarial training, where the model is exposed to adversarial examples during training, can improve robustness. Input validation and sanitization help prevent malicious data from entering the system. Regular audits of data pipelines and model outputs can detect anomalies early. Additionally, using secure model deployment practices—such as containerization, network segmentation, and access controls—reduces the attack surface.
Here’s a simple Python example of generating adversarial examples using the Fast Gradient Sign Method (FGSM) with PyTorch:
python
import torch
def fgsm_attack(model, loss_fn, data, target, epsilon):
data.requires_grad = True
output = model(data)
loss = loss_fn(output, target)
model.zero_grad()
loss.backward()
data_grad = data.grad.data
perturbed_data = data + epsilon * data_grad.sign()
return perturbed_data
Created/Modified files during execution:
print("No files created; this is an in-memory example.")This function perturbs the input data to test the model’s resilience to adversarial attacks.
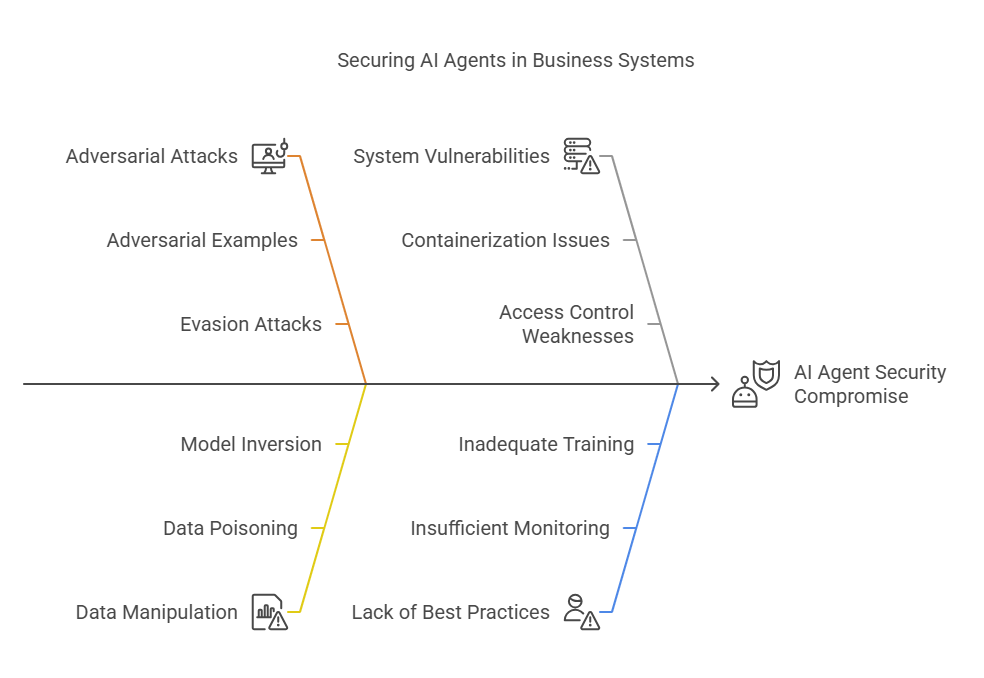
#### 7.2 Security Mechanisms Throughout the Agent Lifecycle
Security must be embedded at every stage of the AI agent lifecycle—from development and deployment to monitoring and updates. During development, code reviews, static analysis, and dependency checks help identify vulnerabilities early. In deployment, containerization (e.g., Docker), orchestration (e.g., Kubernetes), and secrets management (e.g., HashiCorp Vault) ensure that agents run in isolated, controlled environments.
Continuous monitoring is essential for detecting security incidents in real time. Integrating logging and alerting systems (such as ELK Stack, Prometheus, or cloud-native tools) allows teams to track suspicious activity, failed authentications, or unexpected agent behavior. Automated incident response workflows can be triggered when anomalies are detected, minimizing the impact of attacks.
For example, you can use Python’s logging module to record security-relevant events:
python
import logging
logging.basicConfig(filename='security.log', level=logging.WARNING)
def authenticate(user, password):
if not is_valid(user, password):
logging.warning(f"Failed login attempt for user: {user}")
return False
return True
Created/Modified files during execution:
print("security.log")This ensures that failed authentication attempts are logged for further analysis.
#### 7.3 Best Practices for Reliability and Privacy
Ensuring the reliability and privacy of AI agents involves both technical and organizational measures. Regularly updating dependencies and patching vulnerabilities is critical to prevent exploitation. Implementing redundancy and failover mechanisms—such as load balancing, backup models, and automated rollbacks—improves system resilience.
Privacy-preserving techniques, such as differential privacy, federated learning, and encrypted data storage, help protect sensitive information handled by AI agents. Access to models and data should be strictly controlled, with role-based access and audit trails to ensure accountability.
A practical example of using differential privacy in Python is with the `diffprivlib` library:
python
from diffprivlib.mechanisms import Laplace
# Add Laplace noise for differential privacy
sensitive_value = 42
epsilon = 1.0
laplace_mech = Laplace(epsilon=epsilon, sensitivity=1)
private_value = laplace_mech.randomise(sensitive_value)
print("Private value:", private_value)
Created/Modified files during execution:
print("No files created; this is an in-memory example.")This code adds noise to a sensitive value, helping to protect individual privacy in data processing.
Tools and Platforms for AI Agent Lifecycle Management
Managing the lifecycle of AI agents—from development and deployment to monitoring, self-healing, and continuous updates—requires a robust set of tools and platforms. For experienced programmers, the right technology stack not only accelerates workflows but also ensures reproducibility, scalability, and compliance. In this section, we explore the most important categories of tools and platforms that support effective AI agent lifecycle management, with practical examples and recommendations.
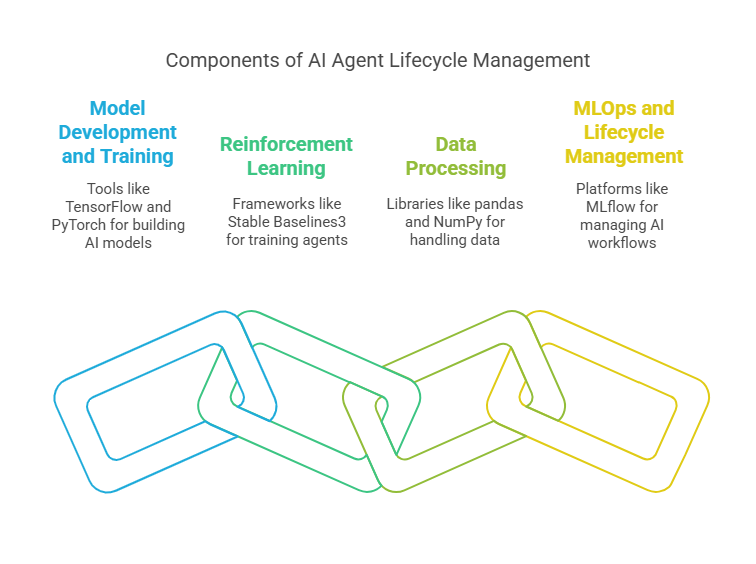
8.1 Overview of Popular Frameworks and Libraries
A modern AI agent stack typically combines several open-source and commercial frameworks. For model development and training, libraries like TensorFlow, PyTorch, and scikit-learn are industry standards, offering flexibility and a rich ecosystem of extensions. For reinforcement learning, Stable Baselines3 and Ray RLlib provide high-level abstractions and scalable training capabilities. Data processing is often handled with pandas, NumPy, and Dask for distributed workloads.
For MLOps and lifecycle management, tools such as MLflow, DVC, and Kubeflow enable experiment tracking, model versioning, and pipeline orchestration. MLflow, for example, allows you to log parameters, metrics, and artifacts for each experiment, making it easy to compare runs and reproduce results.
Here’s a simple example of logging a model training run with MLflow in Python:
python
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load data
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
with mlflow.start_run():
model = RandomForestClassifier()
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
mlflow.log_metric("accuracy", accuracy)
mlflow.sklearn.log_model(model, "model")
Created/Modified files during execution:
print("mlruns/") # MLflow creates a tracking directoryThis code logs the model and its accuracy, making it easy to track and compare experiments.
#### 8.2 MLOps and ModelOps Platforms
MLOps platforms provide end-to-end support for the AI agent lifecycle, from data ingestion and model training to deployment, monitoring, and governance. Popular platforms include MLflow, Kubeflow, Dataiku, and IBM Watson OpenScale. These platforms offer features such as automated pipelines, model versioning, drift detection, and compliance dashboards.
For example, Kubeflow enables you to define and run machine learning pipelines on Kubernetes, supporting scalable, reproducible workflows. Dataiku provides a unified interface for data preparation, model training, deployment, and monitoring, making it suitable for enterprise-scale projects. IBM Watson OpenScale adds explainability, fairness monitoring, and automated retraining to deployed models, helping organizations meet regulatory requirements.
#### 8.3 Automation and Orchestration
Automation is essential for managing complex AI agent workflows. Orchestration tools like Apache Airflow, Prefect, and Watson Pipelines allow you to schedule, monitor, and manage multi-step processes, such as data preprocessing, model training, evaluation, and deployment. These tools support dependency management, error handling, and integration with cloud services.
For instance, a typical Airflow DAG (Directed Acyclic Graph) might automate the daily retraining and deployment of an AI agent:
python
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
def train_model():
# Training logic here
print("Model trained.")
def deploy_model():
# Deployment logic here
print("Model deployed.")
with DAG('ai_agent_lifecycle', start_date=datetime(2024, 1, 1), schedule_interval='@daily') as dag:
train = PythonOperator(task_id='train_model', python_callable=train_model)
deploy = PythonOperator(task_id='deploy_model', python_callable=deploy_model)
train >> deployBest Practices and Recommendations for AI Agent Lifecycle Management
Managing the lifecycle of AI agents is a complex, multi-stage process that requires careful planning, robust tooling, and a commitment to quality and compliance. By following best practices, programmers can ensure their AI agents are reliable, reproducible, and ready for production at scale. Below, we explore the most important recommendations for each stage of the lifecycle.
9.1 Ensuring Reproducibility and Traceability
Reproducibility is fundamental in AI development. It means that anyone should be able to rerun your code and obtain the same results, given the same data and environment. This is crucial for debugging, auditing, and collaboration.
To achieve reproducibility, always version your code, data, and models. Use Git for code versioning, and tools like DVC (Data Version Control) or MLflow for tracking datasets and model artifacts. These tools allow you to link specific data and model versions to code commits, making it easy to trace the origin of any result.
For example, with DVC, you can track a dataset and a model as follows:
python
# Initialize DVC in your project
!dvc init
# Add a dataset to DVC tracking
!dvc add data/train.csv
# Add a trained model to DVC tracking
!dvc add models/model.pkl
# Commit changes to Git
!git add data/train.csv.dvc models/model.pkl.dvc .dvc/config
!git commit -m "Track data and model with DVC"
Created/Modified files during execution:
print("data/train.csv.dvc")
print("models/model.pkl.dvc")
print(".dvc/config")This workflow ensures that every model version is fully traceable and reproducible.
#### 9.2 Automating Testing and Validation
Automated testing is essential for maintaining code quality and preventing regressions. In the context of AI agents, this means not only unit and integration tests for your code, but also validation checks for your data and models.
Use frameworks like `pytest` for code testing, and tools like Great Expectations or TensorFlow Data Validation for data checks. Incorporate these tests into your CI/CD pipelines to catch issues early.
Here’s a simple example of a test that checks model accuracy:
python
def test_model_accuracy():
from joblib import load
model = load("models/model.pkl")
X_test, y_test = ... # Load your test data
accuracy = model.score(X_test, y_test)
assert accuracy > 0.85, "Model accuracy below threshold!"
Created/Modified files during execution:
print("No files created; this is an in-memory example.")Automated validation ensures that changes in code or data do not introduce unexpected behavior.
#### 9.3 Monitoring and Feedback Loops
Continuous monitoring is vital for detecting data drift, performance degradation, and anomalies in production. Monitor both technical metrics (like latency and error rates) and business metrics (such as conversion rates or user engagement).
Set up automated alerts for threshold violations and implement feedback loops for retraining or rolling back models when necessary. Tools like Prometheus, Grafana, and cloud-native monitoring solutions can be integrated with your AI pipelines.
For example, you can log predictions and compare them with actual outcomes to detect drift:
python
import pandas as pd
def log_predictions(predictions, actuals, log_file="predictions_log.csv"):
df = pd.DataFrame({"prediction": predictions, "actual": actuals})
df.to_csv(log_file, mode='a', header=False, index=False)
Created/Modified files during execution:
print("predictions_log.csv")Regularly analyze these logs to determine when retraining is needed.
#### 9.4 Documentation and Knowledge Sharing
Comprehensive documentation is crucial for team productivity and long-term maintainability. Document your code, data pipelines, model architectures, and the rationale behind key decisions. Use tools like Sphinx, MkDocs, or Jupyter Notebooks for technical documentation, and maintain clear README files and onboarding guides.
Encourage knowledge sharing through code reviews, internal wikis, and regular team meetings. This not only improves code quality but also fosters a culture of collaboration and continuous learning.
#### 9.5 Compliance, Ethics, and Responsible AI
AI agents must comply with internal policies and external regulations, especially in sensitive domains like finance or healthcare. Implement audit trails for data and model changes, and ensure your models are explainable and fair.
Adopt frameworks for responsible AI, such as IBM’s OpenScale or Google’s Model Card Toolkit, to monitor fairness, transparency, and bias. Regularly review your models for compliance and ethical considerations, and be prepared to provide documentation for audits.
Future Trends and Challenges in AI Agent Lifecycle Management
The field of AI agent lifecycle management is rapidly evolving, driven by advances in AI research, increasing deployment scale, and growing demands for reliability, security, and ethical compliance. For experienced programmers and AI practitioners, understanding emerging trends and anticipating future challenges is essential to build robust, scalable, and responsible AI systems. This article explores key future directions and challenges shaping the lifecycle management of AI agents.
10.1 Integration of Generative AI and Foundation Models
One of the most significant trends is the rise of foundation models—large-scale pretrained models such as GPT, BERT, and diffusion models—that serve as versatile building blocks for AI agents. Lifecycle management must adapt to handle these models’ unique characteristics, including their size, complexity, and continuous evolution.
Managing foundation models involves challenges like efficient fine-tuning, versioning large model weights, and monitoring for concept drift as these models are adapted to specific tasks. Additionally, integrating generative AI capabilities into agents opens new possibilities for creativity, natural language understanding, and autonomous decision-making, but also raises concerns about control, bias, and explainability.
10.2 Automation and AI-Driven Lifecycle Management
Automation will play an increasingly central role in AI agent lifecycle management. Automated pipelines for data preprocessing, model training, validation, deployment, and monitoring reduce manual effort and accelerate time to market.
Future systems will leverage AI-driven automation to optimize hyperparameters, detect anomalies, and trigger retraining without human intervention. Self-healing AI agents that can diagnose and correct their own failures or performance degradation will become more common, improving resilience and reducing downtime.
10.3 Scaling AI Agents in Distributed and Edge Environments
As AI agents are deployed across distributed cloud infrastructures and edge devices, lifecycle management must address challenges related to scalability, latency, and heterogeneity.
Managing distributed agents requires robust orchestration frameworks that handle communication, synchronization, and conflict resolution. Edge deployments introduce constraints on compute, memory, and connectivity, demanding lightweight models and efficient update mechanisms. Ensuring consistent model versions and secure updates across diverse environments will be critical.
10.4 Enhanced Security, Privacy, and Ethical Governance
Security and privacy concerns will intensify as AI agents become more autonomous and embedded in critical systems. Lifecycle management must incorporate advanced defenses against adversarial attacks, data poisoning, and model theft.
Ethical governance frameworks will be integrated into lifecycle processes to ensure fairness, transparency, and accountability. This includes continuous bias monitoring, explainability tools, and compliance with evolving regulations such as the EU AI Act.
10.5 Human-in-the-Loop and Collaborative AI Agents
Future AI agents will increasingly operate in collaboration with humans, requiring lifecycle management to support interactive learning, feedback incorporation, and adaptive behavior.
Human-in-the-loop systems enable continuous improvement by leveraging expert input during deployment. Managing these feedback loops, ensuring data quality, and balancing automation with human oversight will be key challenges.
10.6 Research Directions and Emerging Technologies
Promising research areas impacting lifecycle management include self-supervised learning, meta-learning, and multi-agent reinforcement learning. These approaches aim to create more adaptable, data-efficient, and cooperative AI agents.
Emerging technologies such as federated learning and blockchain-based provenance tracking offer new ways to manage data privacy and model traceability across decentralized environments.
Artificial Intelligence in Practice: How to Deploy AI Models in Real-World Projects
MLOps in Practice: Automation and Scaling of AI Model Deployments
Next-Generation Programming: Working Side by Side with AI Agents

