
Introduction to Federated Learning
In the era of big data and artificial intelligence, the demand for privacy-preserving machine learning solutions is stronger than ever. Traditional AI models are typically trained on centralized datasets, which often requires collecting sensitive user data in one location. This approach raises significant privacy concerns, especially in sectors like healthcare, finance, and personal devices, where data confidentiality is paramount.
Federated Learning is an innovative paradigm that addresses these concerns by enabling collaborative model training without the need to share raw data. Instead of sending data to a central server, federated learning allows individual devices or organizations (clients) to train models locally on their own data. Only the model updates—such as gradients or weights—are sent to a central server, which aggregates them to improve the global model. This decentralized approach ensures that sensitive information never leaves its source, significantly reducing the risk of data breaches and unauthorized access.
The growing need for privacy-preserving AI is driven by stricter data protection regulations (like GDPR and HIPAA), increased user awareness, and the proliferation of smart devices generating vast amounts of personal data. Federated learning not only helps organizations comply with these regulations but also builds user trust by keeping their data private.
Key benefits of federated learning include enhanced privacy, reduced data transfer costs, and the ability to leverage diverse, distributed datasets that would otherwise remain siloed. This makes federated learning a powerful tool for industries seeking to harness the full potential of AI while respecting user privacy.
Core Concepts of Federated Learning
To understand how federated learning works in practice, it’s important to grasp its foundational concepts and how they differ from traditional machine learning approaches.
Centralized vs. Decentralized Learning
In centralized learning, all data is collected and stored in a single location, where the model is trained. This setup is efficient for computation but risky for privacy. In contrast, federated learning adopts a decentralized approach: data remains on local devices or servers, and only model parameters are communicated. This shift fundamentally changes how data is managed and protected.
The Federated Averaging Algorithm
At the heart of federated learning is the Federated Averaging (FedAvg) algorithm. The process typically works as follows:
The central server initializes a global model and sends it to selected clients.
Each client trains the model locally on its own data for a few epochs.
The clients send their updated model parameters (not raw data) back to the server.
The server aggregates these updates—usually by averaging them—to produce a new global model.
This process repeats for multiple rounds until the model converges.
This approach allows the global model to benefit from the collective knowledge of all clients without ever accessing their private data.
Data Partitioning Strategies: Horizontal and Vertical Federated Learning
Federated learning can be implemented in different ways depending on how data is distributed:
Horizontal Federated Learning (Sample-based): Clients have datasets with the same features but different samples. For example, hospitals in different regions each have patient records with the same structure but for different individuals.
Vertical Federated Learning (Feature-based): Clients have datasets with different features but overlapping samples. For instance, a bank and an e-commerce company may both have information about the same customers, but each holds different types of data (financial vs. purchasing behavior).
Understanding these partitioning strategies is crucial for designing federated learning systems that fit specific organizational needs and data landscapes.
Setting Up a Federated Learning System
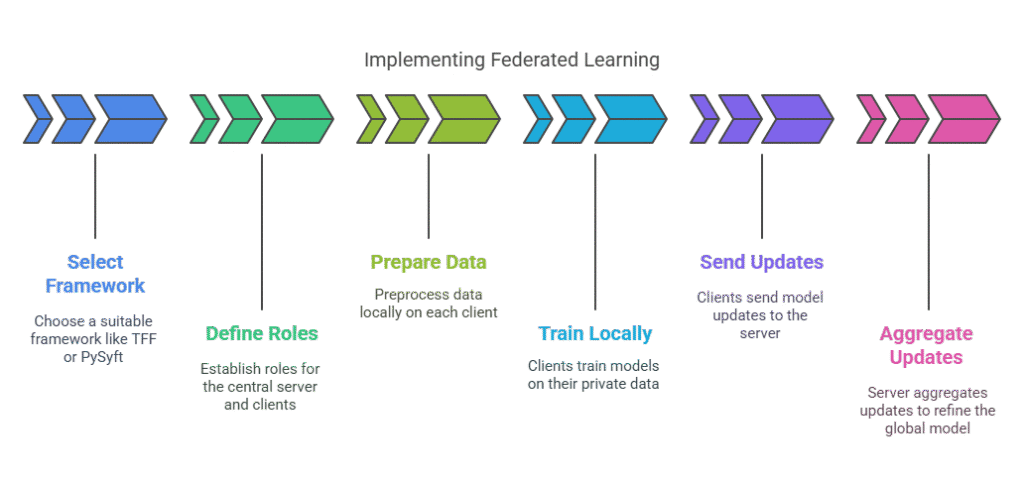
Implementing federated learning in practice requires careful planning, the right tools, and a clear understanding of the system’s architecture. The process begins with selecting an appropriate framework, defining the roles of each participant, and preparing the data for decentralized training.
Choosing the Right Framework
Several open-source frameworks make federated learning accessible to practitioners. Popular options include TensorFlow Federated (TFF), PySyft, and Flower. These frameworks provide abstractions for managing distributed clients, orchestrating communication, and aggregating model updates securely. The choice of framework depends on your preferred programming language, scalability needs, and integration with existing machine learning pipelines.
Defining the Roles: Central Server and Client Devices
A typical federated learning system consists of a central server and multiple client devices (such as smartphones, hospitals, or banks). The central server is responsible for initializing the global model, coordinating training rounds, and aggregating updates. Clients perform local training on their private data and send only the model updates back to the server. This division of roles ensures that sensitive data never leaves the client’s environment.
Data Preprocessing and Feature Engineering for Federated Settings
Data preparation is a critical step in federated learning. Since data remains decentralized, preprocessing and feature engineering must be performed locally on each client. This includes handling missing values, normalizing features, and encoding categorical variables. Consistency across clients is essential—if each client processes data differently, the aggregated model may not converge or perform well. Establishing standardized preprocessing pipelines and sharing feature engineering scripts can help maintain uniformity.
Addressing Challenges in Federated Learning
While federated learning offers significant privacy benefits, it also introduces unique technical and organizational challenges. Overcoming these obstacles is key to building robust and effective federated systems.
Communication Costs and Bandwidth Limitations
Federated learning involves frequent communication between the central server and clients, especially during model update exchanges. In environments with limited bandwidth or unreliable connections (such as mobile networks), this can become a bottleneck. Techniques like model compression, update sparsification, and reducing the frequency of communication rounds can help mitigate these issues.
Handling Non-IID Data (Non-Independent and Identically Distributed)
In federated settings, data on each client is often non-IID—meaning it does not follow the same distribution across all clients. For example, users of a mobile keyboard app may have different typing habits, or hospitals may serve different patient populations. This heterogeneity can slow down model convergence and reduce overall performance. Solutions include personalized federated learning (where models are partially tailored to each client), clustering similar clients, or using advanced aggregation methods that account for data diversity.
Client Selection and Participation Incentives
Not all clients are available or willing to participate in every training round. Devices may be offline, have low battery, or lack sufficient computational resources. Designing fair and efficient client selection strategies is crucial. Additionally, in commercial or collaborative environments, providing incentives—such as rewards or access to improved models—can encourage participation and data sharing.
Security and Privacy Considerations in Federated Learning
While federated learning is designed to enhance privacy by keeping raw data on local devices, it is not immune to security and privacy risks. Addressing these concerns is essential for building trustworthy AI systems, especially in sensitive domains like healthcare and finance.
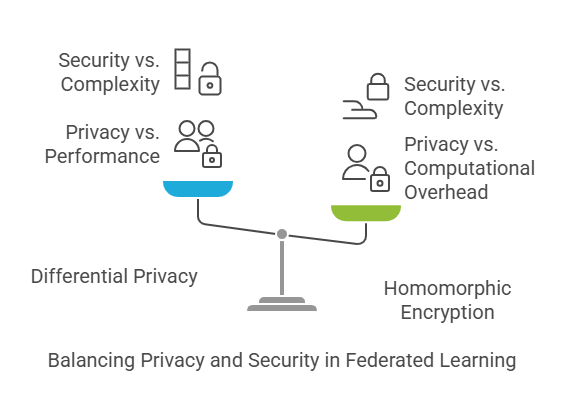
Differential Privacy in Federated Learning
Differential privacy is a mathematical framework that ensures individual data points cannot be reverse-engineered from aggregated results. In federated learning, this is typically achieved by adding carefully calibrated noise to model updates before they are sent from clients to the central server. This approach protects user privacy even if the server is compromised or if an attacker tries to infer information from the model’s parameters. Implementing differential privacy requires balancing privacy guarantees with model accuracy, as excessive noise can degrade performance.
Homomorphic Encryption for Secure Aggregation
Homomorphic encryption allows computations to be performed directly on encrypted data. In federated learning, clients can encrypt their model updates before sending them to the server. The server then aggregates these encrypted updates without ever seeing the raw values, and only the final result is decrypted. This technique ensures that even if the server is compromised, individual updates remain confidential. While homomorphic encryption adds computational overhead, it is a powerful tool for scenarios where data sensitivity is paramount.
Mitigating Adversarial Attacks and Data Poisoning
Federated learning systems are vulnerable to adversarial attacks, such as data poisoning, where malicious clients intentionally submit harmful updates to corrupt the global model. Defending against these threats involves robust aggregation methods (like median or trimmed mean instead of simple averaging), anomaly detection to identify suspicious updates, and secure client authentication. Regular audits and monitoring can further reduce the risk of successful attacks.
Real-World Applications of Federated Learning
Federated learning is not just a theoretical concept—it is already transforming industries by enabling collaborative AI without compromising privacy. Here are some of the most impactful real-world applications:
Healthcare: Collaborative Medical Research
Hospitals and research institutions often possess valuable patient data but are restricted from sharing it due to privacy regulations. Federated learning allows these organizations to collaboratively train models for disease prediction, medical imaging analysis, and drug discovery without exposing sensitive patient information. This accelerates medical research and improves diagnostic accuracy while maintaining compliance with data protection laws.
Finance: Fraud Detection and Risk Assessment
Banks and financial institutions face constant threats from fraud and cybercrime. By using federated learning, multiple organizations can jointly develop robust fraud detection models without sharing proprietary or customer data. This collective intelligence leads to more accurate risk assessment and faster detection of suspicious activities, benefiting the entire financial ecosystem.
IoT: Smart Devices and Edge Computing
The proliferation of smart devices—such as smartphones, wearables, and home assistants—generates vast amounts of personal data. Federated learning enables these devices to collaboratively improve AI models (like voice recognition or predictive text) while keeping user data local. This approach not only enhances privacy but also reduces the need for constant data transmission, saving bandwidth and energy.
Implementing Federated Learning with Python
Bringing federated learning from theory to practice is now more accessible than ever, thanks to open-source frameworks and Python’s rich ecosystem. Implementing a federated learning system involves simulating distributed data, orchestrating local training, and aggregating model updates—all while ensuring privacy and efficiency.
Step-by-Step Example Using TensorFlow Federated
TensorFlow Federated (TFF) is one of the most popular frameworks for federated learning in Python. It allows you to simulate federated environments and experiment with different algorithms. The typical workflow includes:
Simulating Client Data:
You can partition a dataset (such as MNIST or CIFAR-10) to represent data held by different clients. Each client receives a unique subset, mimicking real-world data distribution.
Defining the Model:
You create a standard TensorFlow model (e.g., a simple neural network for image classification) that will be trained locally on each client’s data.
Federated Training Loop:
TFF handles the orchestration of sending the global model to clients, performing local training, collecting updates, and aggregating them on the server. This process repeats for several rounds until the model converges.
Sample Python Code Snippet:
python
import tensorflow as tf
import tensorflow_federated as tff
# Define a simple model
def model_fn():
return tff.learning.from_keras_model(
keras_model=tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(10, activation='softmax')
]),
input_spec=... # specify input spec for client data
)
# Simulate federated data
federated_data = [...] # List of client datasets
# Build federated averaging process
iterative_process = tff.learning.build_federated_averaging_process(model_fn)
state = iterative_process.initialize()
for round_num in range(1, 11):
state, metrics = iterative_process.next(state, federated_data)
print(f'Round {round_num}, metrics={metrics}')Visualizing Results and Evaluating Performance
After training, you can evaluate the global model’s performance on a held-out test set and visualize metrics such as accuracy, loss, and convergence speed. This helps identify whether the federated approach is effective and if further tuning is needed.
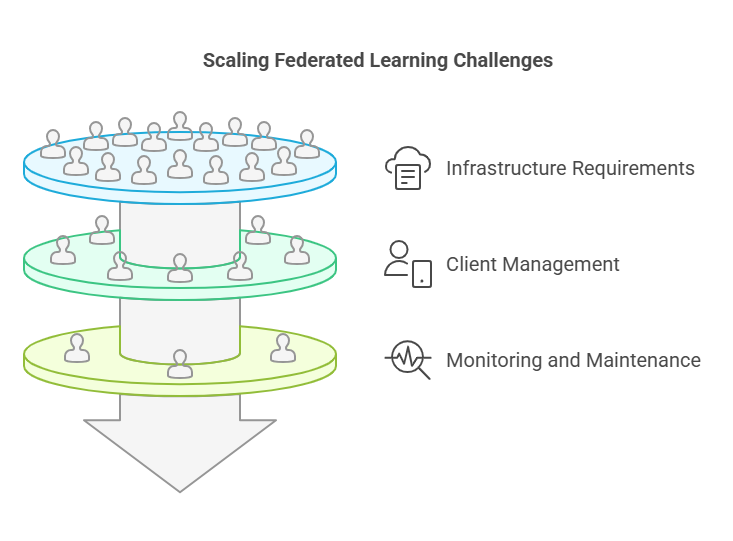
Scaling Federated Learning for Enterprise
Deploying federated learning at an enterprise scale introduces new challenges and opportunities. As the number of clients grows—from dozens to thousands or even millions—organizations must address infrastructure, management, and monitoring complexities.
Infrastructure Requirements and Cloud Integration
Large-scale federated learning often relies on cloud platforms to coordinate training, manage client connections, and store global models. Enterprises may use container orchestration (like Kubernetes) to dynamically allocate resources and ensure high availability. Integration with existing data pipelines and security protocols is essential for seamless operation.
Managing a Large Number of Clients
With many clients, issues such as device heterogeneity, varying network conditions, and inconsistent participation become more pronounced. Enterprises must implement robust client selection strategies, load balancing, and fallback mechanisms to handle unreliable or offline clients. Automated monitoring tools can track participation rates and system health in real time.
Monitoring and Maintaining the Federated Learning System
Continuous monitoring is vital to detect anomalies, concept drift, or performance degradation. Enterprises should establish dashboards for tracking key metrics, set up alerts for unusual activity, and schedule regular model evaluations. Maintenance also includes updating models, patching security vulnerabilities, and ensuring compliance with privacy regulations.
The Future of Federated Learning
Federated learning is still a rapidly evolving field, and its future is shaped by both technological advancements and growing societal demands for privacy and responsible AI. Several emerging trends and research directions are poised to expand the impact and capabilities of federated learning in the years ahead.
Emerging Trends and Research Directions
One of the most significant trends is the integration of federated learning with edge computing. As more devices gain computational power, training models directly on the edge—such as smartphones, IoT sensors, and wearables—will become increasingly practical. This not only enhances privacy but also reduces latency and bandwidth usage, making real-time AI applications more feasible.
Another promising direction is the development of more robust algorithms for handling non-IID (non-independent and identically distributed) data, which is a common challenge in federated settings. Researchers are exploring personalized federated learning, where global models are adapted to individual clients, and advanced aggregation techniques that better account for data diversity.
Security and privacy will remain at the forefront, with ongoing work in differential privacy, secure multi-party computation, and homomorphic encryption. These technologies will help ensure that federated learning systems remain resilient against adversarial attacks and data breaches.
Federated Learning on the Edge
The proliferation of edge devices opens new possibilities for federated learning. By enabling AI models to be trained and updated directly on devices like smartphones and smart home appliances, organizations can deliver personalized experiences without ever collecting raw user data. This approach is particularly valuable in healthcare, where sensitive patient data can remain on local devices while still contributing to global medical research.
The Role of Federated Learning in Responsible AI
As AI systems become more pervasive, the need for responsible and ethical AI grows. Federated learning supports responsible AI by minimizing data exposure, enabling compliance with privacy regulations, and empowering users to retain control over their information. In the future, federated learning is likely to play a central role in building AI systems that are not only powerful but also trustworthy and aligned with societal values.
Conclusion
Federated learning represents a transformative shift in how we approach artificial intelligence, offering a practical solution to the growing tension between data-driven innovation and privacy protection. By enabling collaborative model training without centralizing sensitive data, federated learning empowers organizations to unlock the value of distributed datasets while respecting user confidentiality and regulatory requirements.
Key takeaways from this exploration include the importance of understanding federated learning’s core concepts, addressing technical and organizational challenges, and leveraging robust security measures to protect against emerging threats. Real-world applications in healthcare, finance, and IoT demonstrate the tangible benefits of this approach, while advances in Python frameworks and scalable infrastructure make implementation increasingly accessible.
Looking ahead, federated learning is set to play a pivotal role in the future of responsible AI. As research continues and adoption grows, organizations that embrace federated learning will be well-positioned to innovate securely, ethically, and efficiently in a data-driven world.
Building AI Applications: A Guide for Modern Developers
The AI Agent Revolution: Changing the Way We Develop Software
The Programmer and the AI Agent: Human-Machine Collaboration in Modern Projects

